> ## Documentation Index
> Fetch the complete documentation index at: https://docs.bigdata.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Monitor usage
Initially, Bigdata.com API subscriptions were based on **quota limits per service**. As we released additional services, the model evolved to a **credit-based subscription**: credits are shared across services and consumed according to the [Bigdata API pricing](/getting-started/bigdata_api_pricing) table, so you can allocate usage toward the services that matter most to your workflows.
The clearest place to **visualize** current usage is the Developer Playground [**Usage** page](https://platform.bigdata.com/usage) (sign in with your Bigdata account).
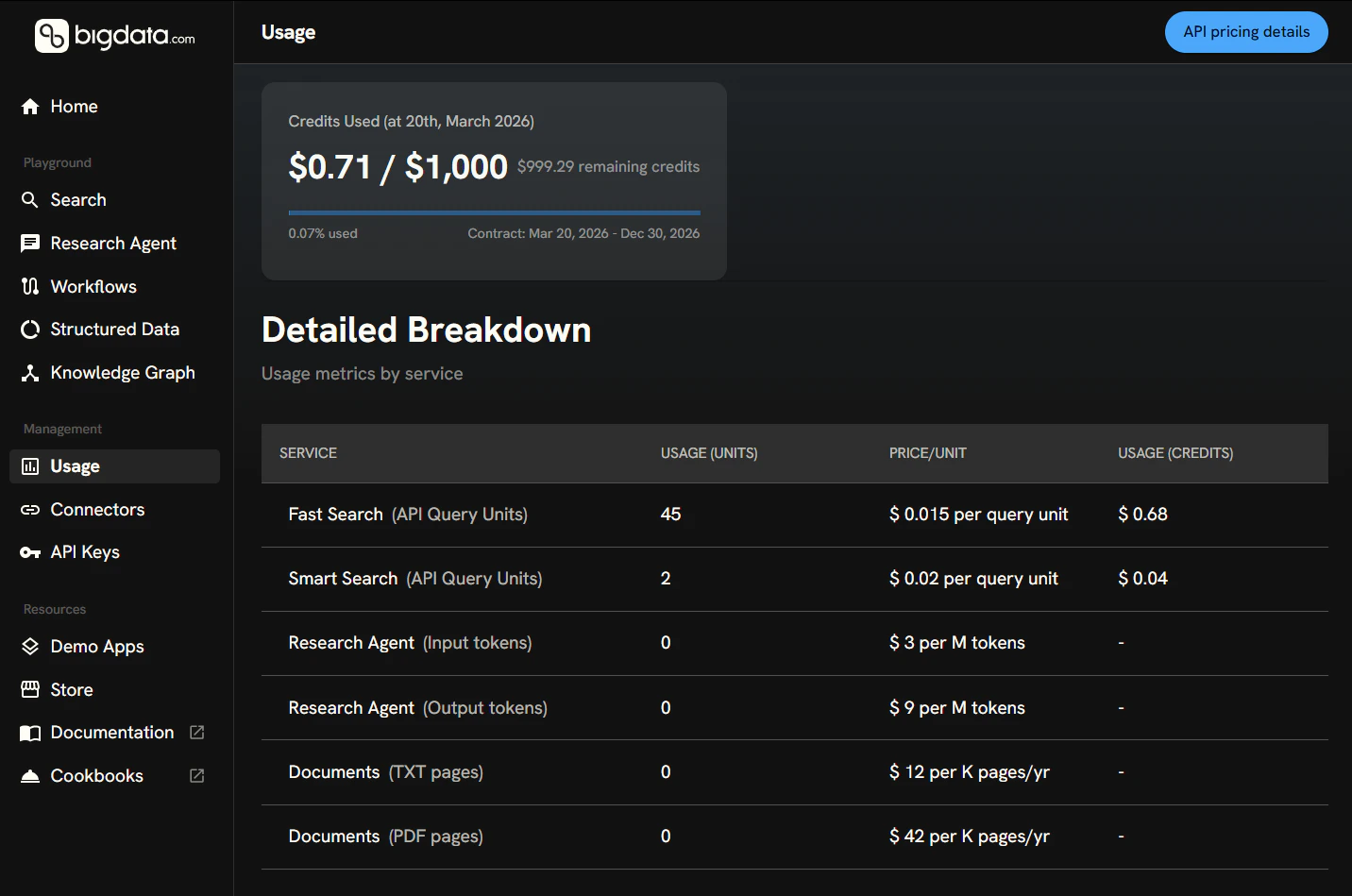 This guide explains how to **monitor usage programmatically**:
* At the [subscription level](#subscription-level): organization-wide quotas or credits
* or [per request](#per-request): Each response includes a `usage` object with details about the usage of the request.
We encourage you to monitor usage and contact us if you would like
assistance in choosing the right subscription plan for your
organization.
## Subscription level
Send a `GET` request to the subscription quotas endpoint. Replace `YOUR_API_KEY` with your API key (same key you use for other Bigdata API calls).
```bash theme={null}
curl 'https://api.bigdata.com/v1/subscription/quotas' \
--header 'X-API-KEY: YOUR_API_KEY'
```
The JSON body indicates whether your organization is on a **credits** subscription (`subscription_type`: `"credits"`) or a **quota** subscription (`subscription_type`: `"quota"`).
The script below calls the same endpoint and prints organization id and subscription type.
Save the script as `print_subscription_usage.py`, set `BIGDATA_API_KEY`, and run `python print_subscription_usage.py`.
```python expandable theme={null}
#!/usr/bin/env python3
"""Print subscription quotas / credit usage from GET /v1/subscription/quotas."""
import json
import os
import sys
import urllib.error
import urllib.request
URL = "https://api.bigdata.com/v1/subscription/quotas"
# Omitted from output (legacy / redundant with other metrics).
SKIP_IDS = frozenset({"text:units", "pages:units"})
def unwrap_subscription_body(parsed):
"""Return (subscription_payload, envelope).
The live API wraps the subscription in ``results`` alongside ``errors`` and
``metadata``. Older or direct responses may expose fields at the top level.
"""
if isinstance(parsed, dict) and isinstance(parsed.get("results"), dict):
return parsed["results"], parsed
return parsed, parsed
def money_cents(value):
if value is None:
return "—"
return f"${value / 100:,.2f}"
def fmt_remaining(value):
if value is None:
return "—"
if isinstance(value, str) and value.lower() == "unlimited":
return "unlimited"
if isinstance(value, (int, float)):
return money_cents(value)
return str(value)
def fmt_quota_scalar(value):
"""Format a quota usage or limit (int, float, or 'unlimited')."""
if value == "unlimited":
return "unlimited"
if isinstance(value, float) and not value.is_integer():
return f"{value:g}"
if isinstance(value, (int, float)):
n = int(value) if isinstance(value, float) else value
return f"{n:,}"
return str(value)
def remaining_cell(used, limit):
if limit == "unlimited":
return "∞"
if used is None or limit is None:
return "—"
try:
rem = float(limit) - float(used)
except (TypeError, ValueError):
return "—"
if abs(rem - round(rem)) < 1e-9:
return f"{int(round(rem)):,}"
return f"{rem:g}"
def row_from_unit(unit):
used = unit.get("units_usage")
limit = unit.get("units_limit")
return (
fmt_quota_scalar(used) if used is not None else "—",
fmt_quota_scalar(limit),
remaining_cell(used, limit),
)
def row_from_credit_unit(unit):
"""Table row for per-metric credit usage (amounts in cents); Used column only."""
used = unit.get("units_usage")
return (money_cents(used) if used is not None else "—",)
def print_table(rows, headers=("Metric", "Used", "Limit", "Remaining")):
"""Print a simple ASCII table (metric left-aligned; other columns right-aligned)."""
if not rows:
return
n = len(headers)
cols = [[headers[i]] + [str(r[i]) for r in rows] for i in range(n)]
widths = [max(len(s) for s in col) for col in cols]
sep = "+" + "".join(f"-{w * '-'}-+" for w in widths)
def fmt_row(cells):
parts = [f"| {cells[0]:<{widths[0]}}"]
for i in range(1, n):
parts.append(f" | {cells[i]:>{widths[i]}}")
parts.append(" |")
return "".join(parts)
print(sep)
print(fmt_row(headers))
print(sep)
for r in rows:
print(fmt_row(r))
print(sep)
def label_for(unit_id, unit, fallback):
if unit is None:
return fallback
return unit.get("display_name") or fallback
def print_units_grouped(quota_units, row_fn, *, credit_tables=False):
"""Print usage tables grouped by product area.
``row_fn(unit)`` returns a tuple: (used, limit, remaining) for quota, or (used) only
for credit tables.
"""
by_id = {u["id"]: u for u in quota_units if u.get("id")}
table_headers = (
("Metric", "Used") if credit_tables else ("Metric", "Used", "Limit", "Remaining")
)
def append_row(metric, unit):
vals = row_fn(unit)
return (metric,) + tuple(vals)
# --- Search Service ---
search_spec = [
("search:smart_unit_read", "Smart Search"),
("search:unit_read", "Fast Search"),
("search:batch_unit_read", "Batch Search"),
]
search_rows = []
for uid, short in search_spec:
u = by_id.get(uid)
if u is None:
continue
search_rows.append(append_row(short, u))
if search_rows:
print("Search Service (API Query Units):")
print_table(search_rows, headers=table_headers)
print()
# --- Research Agent ---
research_sections = [
(
"Base model",
[
"chat:input_tokens",
"chat:output_tokens",
"chat:cached_input_tokens",
],
),
(
"Pro model",
[
"chat:input_tokens_pro_model",
"chat:output_tokens_pro_model",
"chat:cached_input_tokens_pro_model",
],
),
(
"Web Searches",
["chat:external_search"],
),
]
any_research = False
for subsection, ids in research_sections:
rows = []
for uid in ids:
u = by_id.get(uid)
if u is None:
continue
name = label_for(uid, u, uid)
rows.append(append_row(name, u))
if rows:
if not any_research:
print("Research Agent:")
any_research = True
print(f" {subsection}")
print_table(rows, headers=table_headers)
print()
# --- Content Enrichment & Indexing ---
content_spec = [
("private_content:emails", "Emails uploaded"),
]
content_rows = []
for uid, short in content_spec:
u = by_id.get(uid)
if u is None:
continue
content_rows.append(append_row(short, u))
if content_rows:
print("Content Enrichment & Indexing:")
print_table(content_rows, headers=table_headers)
print()
# --- Anything else (except skipped) ---
known = {uid for uid, _ in search_spec}
known.update(uid for _, ids in research_sections for uid in ids)
known.update(uid for uid, _ in content_spec)
known.update(SKIP_IDS)
other_rows = []
for u in quota_units:
uid = u.get("id")
if not uid or uid in known or uid in SKIP_IDS:
continue
name = u.get("display_name") or uid
other_rows.append(append_row(name, u))
if other_rows:
print("Other:")
print_table(other_rows, headers=table_headers)
print()
def print_quota_grouped(quota_units):
print_units_grouped(quota_units, row_from_unit)
def main():
api_key = os.environ.get("BIGDATA_API_KEY")
if not api_key:
print("Set BIGDATA_API_KEY to your API key.", file=sys.stderr)
sys.exit(1)
req = urllib.request.Request(
URL,
headers={"X-API-KEY": api_key, "Accept": "application/json"},
)
try:
with urllib.request.urlopen(req, timeout=30) as resp:
raw = resp.read().decode()
except urllib.error.HTTPError as e:
print(f"HTTP {e.code}: {e.read().decode()}", file=sys.stderr)
sys.exit(1)
parsed = json.loads(raw)
data, envelope = unwrap_subscription_body(parsed)
errors = envelope.get("errors") if isinstance(envelope, dict) else None
if errors:
print("API errors:", file=sys.stderr)
print(json.dumps(errors, indent=2), file=sys.stderr)
sub_type = data.get("subscription_type", "unknown")
print("=" * 72)
print(" Bigdata — subscription usage")
print("=" * 72)
print(f"Organization: {data.get('org_id', '—')}")
print(f"Subscription type: {sub_type}")
print()
if sub_type == "credits":
c = data.get("credits") or {}
print("Credits (organization total)")
print(f" Limit: {money_cents(c.get('limit'))}")
print(f" Used: {money_cents(c.get('usage'))}")
print(f" Remaining: {fmt_remaining(c.get('remaining'))}")
print()
for i, bill in enumerate(data.get("billing") or [], 1):
period = bill.get("period") or {}
start, end = period.get("start"), period.get("end")
print(f"Billing period {i}: {start} → {end}")
print(f" Credit usage (this period): {money_cents(bill.get('credit_usage'))}")
print()
bill_units = [
u
for u in (bill.get("units") or [])
if u.get("id") not in SKIP_IDS
]
print_units_grouped(bill_units, row_from_credit_unit, credit_tables=True)
elif sub_type == "quota":
units = [
u
for u in (data.get("quota_units") or [])
if u.get("id") not in SKIP_IDS
]
print_quota_grouped(units)
else:
print("Raw response:")
print(json.dumps(parsed, indent=2))
print("=" * 72)
if __name__ == "__main__":
main()
```
**Example output:**
When `subscription_type` is `quota`:
```text theme={null}
========================================================================
Bigdata — subscription usage
========================================================================
Organization: org_2mcHlzgEHGsO8V9XAHEL5J8X80J
Subscription type: quota
Search Service (API Query Units):
+--------------+-------+--------+-----------+
| Metric | Used | Limit | Remaining |
+--------------+-------+--------+-----------+
| Smart Search | 2 | 50,000 | 49,998 |
| Fast Search | 210.1 | 50,000 | 49789.9 |
| Batch Search | 0 | 50,000 | 50,000 |
+--------------+-------+--------+-----------+
Research Agent:
Base model
+----------------------------+---------+-----------+-----------+
| Metric | Used | Limit | Remaining |
+----------------------------+---------+-----------+-----------+
| Base model - Input tokens | 895,877 | 8,000,000 | 7,104,123 |
| Base model - Output tokens | 35,325 | 8,000,000 | 7,964,675 |
+----------------------------+---------+-----------+-----------+
Pro model
+---------------------------+------+---------+-----------+
| Metric | Used | Limit | Remaining |
+---------------------------+------+---------+-----------+
| Pro model - Input tokens | 0 | 400,000 | 400,000 |
| Pro model - Output tokens | 0 | 200,000 | 200,000 |
+---------------------------+------+---------+-----------+
Web Searches
+--------------+------+-------+-----------+
| Metric | Used | Limit | Remaining |
+--------------+------+-------+-----------+
| Web Searches | 0 | 1,000 | 1,000 |
+--------------+------+-------+-----------+
Content Enrichment & Indexing:
+--------------------+------+-------+-----------+
| Metric | Used | Limit | Remaining |
+--------------------+------+-------+-----------+
| TXT pages uploaded | 0 | 1,000 | 1,000 |
| PDF pages uploaded | 0 | 1,000 | 1,000 |
| Emails uploaded | 0 | 1,000 | 1,000 |
+--------------------+------+-------+-----------+
========================================================================
```
Example output when `subscription_type` is `credits` (values are illustrative):
```text theme={null}
========================================================================
Bigdata — subscription usage
========================================================================
Organization: org_3BCd4XgFmo7cI4whHZuvRmaDqZk
Subscription type: credits
Credits (organization total)
Limit: $1,000.00
Used: $0.77
Remaining: $999.23
Billing period 1: 2026-03-20 → 2026-12-30
Credit usage (this period): $0.77
Search Service (API Query Units):
+--------------+-------+
| Metric | Used |
+--------------+-------+
| Smart Search | $0.05 |
| Fast Search | $0.45 |
| Batch Search | $0.00 |
+--------------+-------+
Research Agent:
Base model
+----------------------------------+-------+
| Metric | Used |
+----------------------------------+-------+
| Base model - Input tokens | $0.00 |
| Base model - Output tokens | $0.00 |
| Base model - Cached input tokens | $0.00 |
+----------------------------------+-------+
Pro model
+---------------------------------+-------+
| Metric | Used |
+---------------------------------+-------+
| Pro model - Input tokens | $0.00 |
| Pro model - Output tokens | $0.00 |
| Pro model - Cached input tokens | $0.00 |
+---------------------------------+-------+
Other:
+------------------------+-------+
| Metric | Used |
+------------------------+-------+
| chat:external_searches | $0.00 |
+------------------------+-------+
========================================================================
```
Use the method `get_details` to retrieve subscription details:
```python theme={null}
from bigdata_client import Bigdata
bigdata = Bigdata()
subscription_details = bigdata.subscription.get_details()
```
### API Query Unit
Bigdata.com measures the amount of retrieved data with API Query Units; each unit allows retrieval of 10 text chunks.
```python theme={null}
subscription_details = bigdata.subscription.get_details()
print(f"API Query Unit monitoring")
print(f"Total: {subscription_details.organization_quota.query_unit.total}")
print(f"Used: {subscription_details.organization_quota.query_unit.used}")
print(f"Remaining: {subscription_details.organization_quota.query_unit.remaining}")
```
Output:
```text theme={null}
API Query Unit monitoring
Total: 50000
Used: 2025
Remaining: 47975
```
The method `search.run()` accepts a parameter to specify the number of
documents or chunks to retrieve. Every ten retrieved chunks count as one
API Query Unit.
You can control the usage by specifying the number of chunks to retrieve
with the parameter `ChunkLimit`:
* `search.run(ChunkLimit(100))` will retrieve a maximum of 100 chunks
and therefore will consume a maximum of 10 API Query Units. The
response might contain a smaller number of chunks due to discarding
duplicates, so the usage could be lower.
Check the how-to guide [Retrieve limited chunks](/how-to-guides/queries_with_chunk_limit) for more details.
Check the usage of each search run at the [per-request](#per-request) section below.
### Pages of uploaded files
Bigdata.com measures the amount of uploaded files in pages.
#### PDF format
```python theme={null}
subscription_details = bigdata.subscription.get_details()
print(f"PDF files pages monitoring")
print(f"Total: {subscription_details.organization_quota.pdf_upload_pages.total}")
print(f"Used: {subscription_details.organization_quota.pdf_upload_pages.used}")
print(f"Remaining: {subscription_details.organization_quota.pdf_upload_pages.remaining}")
```
Output:
```text theme={null}
PDF files pages monitoring
Total: 20000
Used: 13923
Remaining: 6077
```
#### Other format (CSV, XML, JSON, HTML, TXT, DOCX…)
```python theme={null}
subscription_details = bigdata.subscription.get_details()
print(f"Generic file pages monitoring")
print(f"Total: {subscription_details.organization_quota.file_upload_pages.total}")
print(f"Used: {subscription_details.organization_quota.file_upload_pages.used}")
print(f"Remaining: {subscription_details.organization_quota.file_upload_pages.remaining}")
```
Output:
```text theme={null}
Generic file pages monitoring
Total: 20000
Used: 13923
Remaining: 6077
```
## Per request
### Search Service
Each search response includes a `usage` object reporting how many **API Query Units** that request consumed:
```json theme={null}
"usage": {
"api_query_units": 0.1
}
```
### Research Agent
The Research Agent streams Server-Sent Events. The **`COMPLETE`** event uses `CompleteMessage`, which includes a **`consumption`** array with token usage per model tier (base / pro) for that request. See [`CompleteMessage.consumption`](/api-reference/research-agent/research-agent#response-one-of-0-message-one-of-3-consumption) in the Research Agent API reference.
Each new `search` tracks the amount of retrieved data, and you can consult it at any time with the method `get_usage()`
Initially, the usage of a new search is `0`
```python theme={null}
from bigdata_client.query import Keyword
some_search = bigdata.search.new(query=Keyword("AI in finance"))
print(f"Initial search usage {some_search.get_usage()}")
```
After executing the method `run()`, the method `get_usage()` returns the used Query Units.
The response might contain a smaller number of chunks due to discarding duplicates, so the usage could be lower. Check the how-to guide [Retrieve limited chunks](/how-to-guides/queries_with_chunk_limit) for more details.
```python theme={null}
from bigdata_client.search import ChunkLimit
some_search.run(ChunkLimit(100))
print(f"Current search usage {some_search.get_usage()}")
```
## Any doubts? Get in touch!
Please get in touch with your Account Manager or [support@bigdata.com](mailto:support@bigdata.com) if you have any questions or would like guidance in selecting the best subscription for your needs.
This guide explains how to **monitor usage programmatically**:
* At the [subscription level](#subscription-level): organization-wide quotas or credits
* or [per request](#per-request): Each response includes a `usage` object with details about the usage of the request.
We encourage you to monitor usage and contact us if you would like
assistance in choosing the right subscription plan for your
organization.
## Subscription level
Send a `GET` request to the subscription quotas endpoint. Replace `YOUR_API_KEY` with your API key (same key you use for other Bigdata API calls).
```bash theme={null}
curl 'https://api.bigdata.com/v1/subscription/quotas' \
--header 'X-API-KEY: YOUR_API_KEY'
```
The JSON body indicates whether your organization is on a **credits** subscription (`subscription_type`: `"credits"`) or a **quota** subscription (`subscription_type`: `"quota"`).
The script below calls the same endpoint and prints organization id and subscription type.
Save the script as `print_subscription_usage.py`, set `BIGDATA_API_KEY`, and run `python print_subscription_usage.py`.
```python expandable theme={null}
#!/usr/bin/env python3
"""Print subscription quotas / credit usage from GET /v1/subscription/quotas."""
import json
import os
import sys
import urllib.error
import urllib.request
URL = "https://api.bigdata.com/v1/subscription/quotas"
# Omitted from output (legacy / redundant with other metrics).
SKIP_IDS = frozenset({"text:units", "pages:units"})
def unwrap_subscription_body(parsed):
"""Return (subscription_payload, envelope).
The live API wraps the subscription in ``results`` alongside ``errors`` and
``metadata``. Older or direct responses may expose fields at the top level.
"""
if isinstance(parsed, dict) and isinstance(parsed.get("results"), dict):
return parsed["results"], parsed
return parsed, parsed
def money_cents(value):
if value is None:
return "—"
return f"${value / 100:,.2f}"
def fmt_remaining(value):
if value is None:
return "—"
if isinstance(value, str) and value.lower() == "unlimited":
return "unlimited"
if isinstance(value, (int, float)):
return money_cents(value)
return str(value)
def fmt_quota_scalar(value):
"""Format a quota usage or limit (int, float, or 'unlimited')."""
if value == "unlimited":
return "unlimited"
if isinstance(value, float) and not value.is_integer():
return f"{value:g}"
if isinstance(value, (int, float)):
n = int(value) if isinstance(value, float) else value
return f"{n:,}"
return str(value)
def remaining_cell(used, limit):
if limit == "unlimited":
return "∞"
if used is None or limit is None:
return "—"
try:
rem = float(limit) - float(used)
except (TypeError, ValueError):
return "—"
if abs(rem - round(rem)) < 1e-9:
return f"{int(round(rem)):,}"
return f"{rem:g}"
def row_from_unit(unit):
used = unit.get("units_usage")
limit = unit.get("units_limit")
return (
fmt_quota_scalar(used) if used is not None else "—",
fmt_quota_scalar(limit),
remaining_cell(used, limit),
)
def row_from_credit_unit(unit):
"""Table row for per-metric credit usage (amounts in cents); Used column only."""
used = unit.get("units_usage")
return (money_cents(used) if used is not None else "—",)
def print_table(rows, headers=("Metric", "Used", "Limit", "Remaining")):
"""Print a simple ASCII table (metric left-aligned; other columns right-aligned)."""
if not rows:
return
n = len(headers)
cols = [[headers[i]] + [str(r[i]) for r in rows] for i in range(n)]
widths = [max(len(s) for s in col) for col in cols]
sep = "+" + "".join(f"-{w * '-'}-+" for w in widths)
def fmt_row(cells):
parts = [f"| {cells[0]:<{widths[0]}}"]
for i in range(1, n):
parts.append(f" | {cells[i]:>{widths[i]}}")
parts.append(" |")
return "".join(parts)
print(sep)
print(fmt_row(headers))
print(sep)
for r in rows:
print(fmt_row(r))
print(sep)
def label_for(unit_id, unit, fallback):
if unit is None:
return fallback
return unit.get("display_name") or fallback
def print_units_grouped(quota_units, row_fn, *, credit_tables=False):
"""Print usage tables grouped by product area.
``row_fn(unit)`` returns a tuple: (used, limit, remaining) for quota, or (used) only
for credit tables.
"""
by_id = {u["id"]: u for u in quota_units if u.get("id")}
table_headers = (
("Metric", "Used") if credit_tables else ("Metric", "Used", "Limit", "Remaining")
)
def append_row(metric, unit):
vals = row_fn(unit)
return (metric,) + tuple(vals)
# --- Search Service ---
search_spec = [
("search:smart_unit_read", "Smart Search"),
("search:unit_read", "Fast Search"),
("search:batch_unit_read", "Batch Search"),
]
search_rows = []
for uid, short in search_spec:
u = by_id.get(uid)
if u is None:
continue
search_rows.append(append_row(short, u))
if search_rows:
print("Search Service (API Query Units):")
print_table(search_rows, headers=table_headers)
print()
# --- Research Agent ---
research_sections = [
(
"Base model",
[
"chat:input_tokens",
"chat:output_tokens",
"chat:cached_input_tokens",
],
),
(
"Pro model",
[
"chat:input_tokens_pro_model",
"chat:output_tokens_pro_model",
"chat:cached_input_tokens_pro_model",
],
),
(
"Web Searches",
["chat:external_search"],
),
]
any_research = False
for subsection, ids in research_sections:
rows = []
for uid in ids:
u = by_id.get(uid)
if u is None:
continue
name = label_for(uid, u, uid)
rows.append(append_row(name, u))
if rows:
if not any_research:
print("Research Agent:")
any_research = True
print(f" {subsection}")
print_table(rows, headers=table_headers)
print()
# --- Content Enrichment & Indexing ---
content_spec = [
("private_content:emails", "Emails uploaded"),
]
content_rows = []
for uid, short in content_spec:
u = by_id.get(uid)
if u is None:
continue
content_rows.append(append_row(short, u))
if content_rows:
print("Content Enrichment & Indexing:")
print_table(content_rows, headers=table_headers)
print()
# --- Anything else (except skipped) ---
known = {uid for uid, _ in search_spec}
known.update(uid for _, ids in research_sections for uid in ids)
known.update(uid for uid, _ in content_spec)
known.update(SKIP_IDS)
other_rows = []
for u in quota_units:
uid = u.get("id")
if not uid or uid in known or uid in SKIP_IDS:
continue
name = u.get("display_name") or uid
other_rows.append(append_row(name, u))
if other_rows:
print("Other:")
print_table(other_rows, headers=table_headers)
print()
def print_quota_grouped(quota_units):
print_units_grouped(quota_units, row_from_unit)
def main():
api_key = os.environ.get("BIGDATA_API_KEY")
if not api_key:
print("Set BIGDATA_API_KEY to your API key.", file=sys.stderr)
sys.exit(1)
req = urllib.request.Request(
URL,
headers={"X-API-KEY": api_key, "Accept": "application/json"},
)
try:
with urllib.request.urlopen(req, timeout=30) as resp:
raw = resp.read().decode()
except urllib.error.HTTPError as e:
print(f"HTTP {e.code}: {e.read().decode()}", file=sys.stderr)
sys.exit(1)
parsed = json.loads(raw)
data, envelope = unwrap_subscription_body(parsed)
errors = envelope.get("errors") if isinstance(envelope, dict) else None
if errors:
print("API errors:", file=sys.stderr)
print(json.dumps(errors, indent=2), file=sys.stderr)
sub_type = data.get("subscription_type", "unknown")
print("=" * 72)
print(" Bigdata — subscription usage")
print("=" * 72)
print(f"Organization: {data.get('org_id', '—')}")
print(f"Subscription type: {sub_type}")
print()
if sub_type == "credits":
c = data.get("credits") or {}
print("Credits (organization total)")
print(f" Limit: {money_cents(c.get('limit'))}")
print(f" Used: {money_cents(c.get('usage'))}")
print(f" Remaining: {fmt_remaining(c.get('remaining'))}")
print()
for i, bill in enumerate(data.get("billing") or [], 1):
period = bill.get("period") or {}
start, end = period.get("start"), period.get("end")
print(f"Billing period {i}: {start} → {end}")
print(f" Credit usage (this period): {money_cents(bill.get('credit_usage'))}")
print()
bill_units = [
u
for u in (bill.get("units") or [])
if u.get("id") not in SKIP_IDS
]
print_units_grouped(bill_units, row_from_credit_unit, credit_tables=True)
elif sub_type == "quota":
units = [
u
for u in (data.get("quota_units") or [])
if u.get("id") not in SKIP_IDS
]
print_quota_grouped(units)
else:
print("Raw response:")
print(json.dumps(parsed, indent=2))
print("=" * 72)
if __name__ == "__main__":
main()
```
**Example output:**
When `subscription_type` is `quota`:
```text theme={null}
========================================================================
Bigdata — subscription usage
========================================================================
Organization: org_2mcHlzgEHGsO8V9XAHEL5J8X80J
Subscription type: quota
Search Service (API Query Units):
+--------------+-------+--------+-----------+
| Metric | Used | Limit | Remaining |
+--------------+-------+--------+-----------+
| Smart Search | 2 | 50,000 | 49,998 |
| Fast Search | 210.1 | 50,000 | 49789.9 |
| Batch Search | 0 | 50,000 | 50,000 |
+--------------+-------+--------+-----------+
Research Agent:
Base model
+----------------------------+---------+-----------+-----------+
| Metric | Used | Limit | Remaining |
+----------------------------+---------+-----------+-----------+
| Base model - Input tokens | 895,877 | 8,000,000 | 7,104,123 |
| Base model - Output tokens | 35,325 | 8,000,000 | 7,964,675 |
+----------------------------+---------+-----------+-----------+
Pro model
+---------------------------+------+---------+-----------+
| Metric | Used | Limit | Remaining |
+---------------------------+------+---------+-----------+
| Pro model - Input tokens | 0 | 400,000 | 400,000 |
| Pro model - Output tokens | 0 | 200,000 | 200,000 |
+---------------------------+------+---------+-----------+
Web Searches
+--------------+------+-------+-----------+
| Metric | Used | Limit | Remaining |
+--------------+------+-------+-----------+
| Web Searches | 0 | 1,000 | 1,000 |
+--------------+------+-------+-----------+
Content Enrichment & Indexing:
+--------------------+------+-------+-----------+
| Metric | Used | Limit | Remaining |
+--------------------+------+-------+-----------+
| TXT pages uploaded | 0 | 1,000 | 1,000 |
| PDF pages uploaded | 0 | 1,000 | 1,000 |
| Emails uploaded | 0 | 1,000 | 1,000 |
+--------------------+------+-------+-----------+
========================================================================
```
Example output when `subscription_type` is `credits` (values are illustrative):
```text theme={null}
========================================================================
Bigdata — subscription usage
========================================================================
Organization: org_3BCd4XgFmo7cI4whHZuvRmaDqZk
Subscription type: credits
Credits (organization total)
Limit: $1,000.00
Used: $0.77
Remaining: $999.23
Billing period 1: 2026-03-20 → 2026-12-30
Credit usage (this period): $0.77
Search Service (API Query Units):
+--------------+-------+
| Metric | Used |
+--------------+-------+
| Smart Search | $0.05 |
| Fast Search | $0.45 |
| Batch Search | $0.00 |
+--------------+-------+
Research Agent:
Base model
+----------------------------------+-------+
| Metric | Used |
+----------------------------------+-------+
| Base model - Input tokens | $0.00 |
| Base model - Output tokens | $0.00 |
| Base model - Cached input tokens | $0.00 |
+----------------------------------+-------+
Pro model
+---------------------------------+-------+
| Metric | Used |
+---------------------------------+-------+
| Pro model - Input tokens | $0.00 |
| Pro model - Output tokens | $0.00 |
| Pro model - Cached input tokens | $0.00 |
+---------------------------------+-------+
Other:
+------------------------+-------+
| Metric | Used |
+------------------------+-------+
| chat:external_searches | $0.00 |
+------------------------+-------+
========================================================================
```
Use the method `get_details` to retrieve subscription details:
```python theme={null}
from bigdata_client import Bigdata
bigdata = Bigdata()
subscription_details = bigdata.subscription.get_details()
```
### API Query Unit
Bigdata.com measures the amount of retrieved data with API Query Units; each unit allows retrieval of 10 text chunks.
```python theme={null}
subscription_details = bigdata.subscription.get_details()
print(f"API Query Unit monitoring")
print(f"Total: {subscription_details.organization_quota.query_unit.total}")
print(f"Used: {subscription_details.organization_quota.query_unit.used}")
print(f"Remaining: {subscription_details.organization_quota.query_unit.remaining}")
```
Output:
```text theme={null}
API Query Unit monitoring
Total: 50000
Used: 2025
Remaining: 47975
```
The method `search.run()` accepts a parameter to specify the number of
documents or chunks to retrieve. Every ten retrieved chunks count as one
API Query Unit.
You can control the usage by specifying the number of chunks to retrieve
with the parameter `ChunkLimit`:
* `search.run(ChunkLimit(100))` will retrieve a maximum of 100 chunks
and therefore will consume a maximum of 10 API Query Units. The
response might contain a smaller number of chunks due to discarding
duplicates, so the usage could be lower.
Check the how-to guide [Retrieve limited chunks](/how-to-guides/queries_with_chunk_limit) for more details.
Check the usage of each search run at the [per-request](#per-request) section below.
### Pages of uploaded files
Bigdata.com measures the amount of uploaded files in pages.
#### PDF format
```python theme={null}
subscription_details = bigdata.subscription.get_details()
print(f"PDF files pages monitoring")
print(f"Total: {subscription_details.organization_quota.pdf_upload_pages.total}")
print(f"Used: {subscription_details.organization_quota.pdf_upload_pages.used}")
print(f"Remaining: {subscription_details.organization_quota.pdf_upload_pages.remaining}")
```
Output:
```text theme={null}
PDF files pages monitoring
Total: 20000
Used: 13923
Remaining: 6077
```
#### Other format (CSV, XML, JSON, HTML, TXT, DOCX…)
```python theme={null}
subscription_details = bigdata.subscription.get_details()
print(f"Generic file pages monitoring")
print(f"Total: {subscription_details.organization_quota.file_upload_pages.total}")
print(f"Used: {subscription_details.organization_quota.file_upload_pages.used}")
print(f"Remaining: {subscription_details.organization_quota.file_upload_pages.remaining}")
```
Output:
```text theme={null}
Generic file pages monitoring
Total: 20000
Used: 13923
Remaining: 6077
```
## Per request
### Search Service
Each search response includes a `usage` object reporting how many **API Query Units** that request consumed:
```json theme={null}
"usage": {
"api_query_units": 0.1
}
```
### Research Agent
The Research Agent streams Server-Sent Events. The **`COMPLETE`** event uses `CompleteMessage`, which includes a **`consumption`** array with token usage per model tier (base / pro) for that request. See [`CompleteMessage.consumption`](/api-reference/research-agent/research-agent#response-one-of-0-message-one-of-3-consumption) in the Research Agent API reference.
Each new `search` tracks the amount of retrieved data, and you can consult it at any time with the method `get_usage()`
Initially, the usage of a new search is `0`
```python theme={null}
from bigdata_client.query import Keyword
some_search = bigdata.search.new(query=Keyword("AI in finance"))
print(f"Initial search usage {some_search.get_usage()}")
```
After executing the method `run()`, the method `get_usage()` returns the used Query Units.
The response might contain a smaller number of chunks due to discarding duplicates, so the usage could be lower. Check the how-to guide [Retrieve limited chunks](/how-to-guides/queries_with_chunk_limit) for more details.
```python theme={null}
from bigdata_client.search import ChunkLimit
some_search.run(ChunkLimit(100))
print(f"Current search usage {some_search.get_usage()}")
```
## Any doubts? Get in touch!
Please get in touch with your Account Manager or [support@bigdata.com](mailto:support@bigdata.com) if you have any questions or would like guidance in selecting the best subscription for your needs.