Why It Matters
Understanding how companies are exposed to highly uncertain scenarios and risk channels, like geopolitical and economic risks, is critical for informed decision-making. As shifting policies, sanctions, and trade barriers redefine market dynamics, organizations must proactively assess their vulnerability to emerging threats.What It Does
TheRiskAnalyzer class, part of the bigdata-research-tools package, is purpose-built to meet this challenge. Designed for risk analysts, portfolio managers, and investment professionals, it systematically analyzes corporate exposure to specific risk channels using unstructured data from news, earnings calls, and regulatory filings.
How It Works
TheRiskAnalyzer combines hybrid semantic search, risk factor taxonomies, and structured validation techniques to deliver:
- Targeted extraction of risk signals and supporting evidence from massive unstructured datasets
- Standardized exposure metrics to compare risk across firms, sectors, or portfolios
- Actionable insights that inform investment strategies and enterprise risk decisions
- Time-based monitoring to track how exposure levels shift in response to world events
A Real-World Use Case
This cookbook illustrates the full workflow through a practical example: identifying companies impacted by new U.S. import tariffs on China. You’ll learn how to convert unstructured narrative (news articles) into structured, quantifiable risk intelligence. Ready to get started? Let’s dive in!Prerequisites
To run the Risk Analyzer workflow, you can choose between three options:-
▶️ Colab cookbook
- Use this if you prefer running the workflow in a cloud environment.
- Follow the instructions written directly inside the cookbook.
- API keys must be configured as described within the Colab file itself.
-
💻 GitHub cookbook
- Use this if you prefer working locally or in a custom environment.
- Follow the setup and execution instructions in the
README.md. - API keys are required:
- Option 1: Follow the key setup process described in the
README.md - Option 2: Refer to this guide: How to initialise environment variables
- ❗ When using this method, you must manually add the OpenAI API key:
- ❗ When using this method, you must manually add the OpenAI API key:
- Option 1: Follow the key setup process described in the
-
🐳 Docker Installation
- Docker installation is available for containerized deployment.
- Provides an alternative setup method with containerized deployment, simplifying the environment configuration for those preferring Docker-based solutions.
Setup and Imports
Below is the Python code required for setting up our environment and importing necessary libraries.Defining Your Risk Analysis Parameters
To perform a portfolio risk analysis, we need to define several key parameters:- Main Theme (
main_theme): The risk scenario to analyze (e.g. US Import Tariffs against China) - Focus (
focus): The analyst focus that provides an expert perspective on the scenario and helps break it down into risk factors - Company Universe (
companies): The set of companies to screen - Control Entities (
control_entities): The countries, people, or organizations that characterize the risk scenario - Keywords (
keywords): The key concepts of the risk scenario - Time Period (
start_dateandend_date): The date range over which to run the search - Document Type (
document_type): Specify which documents to search over (transcripts, filings, news) - Fiscal Year (
fiscal_year): If the document type is transcripts or filings, fiscal year needs to be specified - Sources (
sources): Specify set of sources within a document type, for example which news outlets (available via Bigdata API) you wish to search over - Model Selection (
llm_model): The AI model used for semantic analysis - Rerank Threshold (
rerank_threshold): By setting this value, you’re enabling the cross-encoder which reranks the results and selects those whose relevance is above the percentile you specify (0.7 being the 70th percentile). More information on the re-ranker can be found here. - Export Path (
export_path): The path to export the results in an Excel file
Instantiating and Running the Risk Analyzer
The RiskAnalyzer class handles the complete risk analysis workflow:- Taxonomy Creation: Automatically generates a hierarchical tree for US Import Tariffs
- Content Retrieval: Searches news for relevant discussions
- Semantic Labeling: Uses AI to categorize content into appropriate sub-scenarios
- Scoring: Calculates company and industry-level exposure scores
Mindmap a Risk Taxonomy with Bigdata Research Tools
You can leverage Bigdata Research Tools to generate a comprehensive risk taxonomy with an LLM, breaking down a complex risk scenario into well-defined risks and sub-scenarios for more targeted analysis.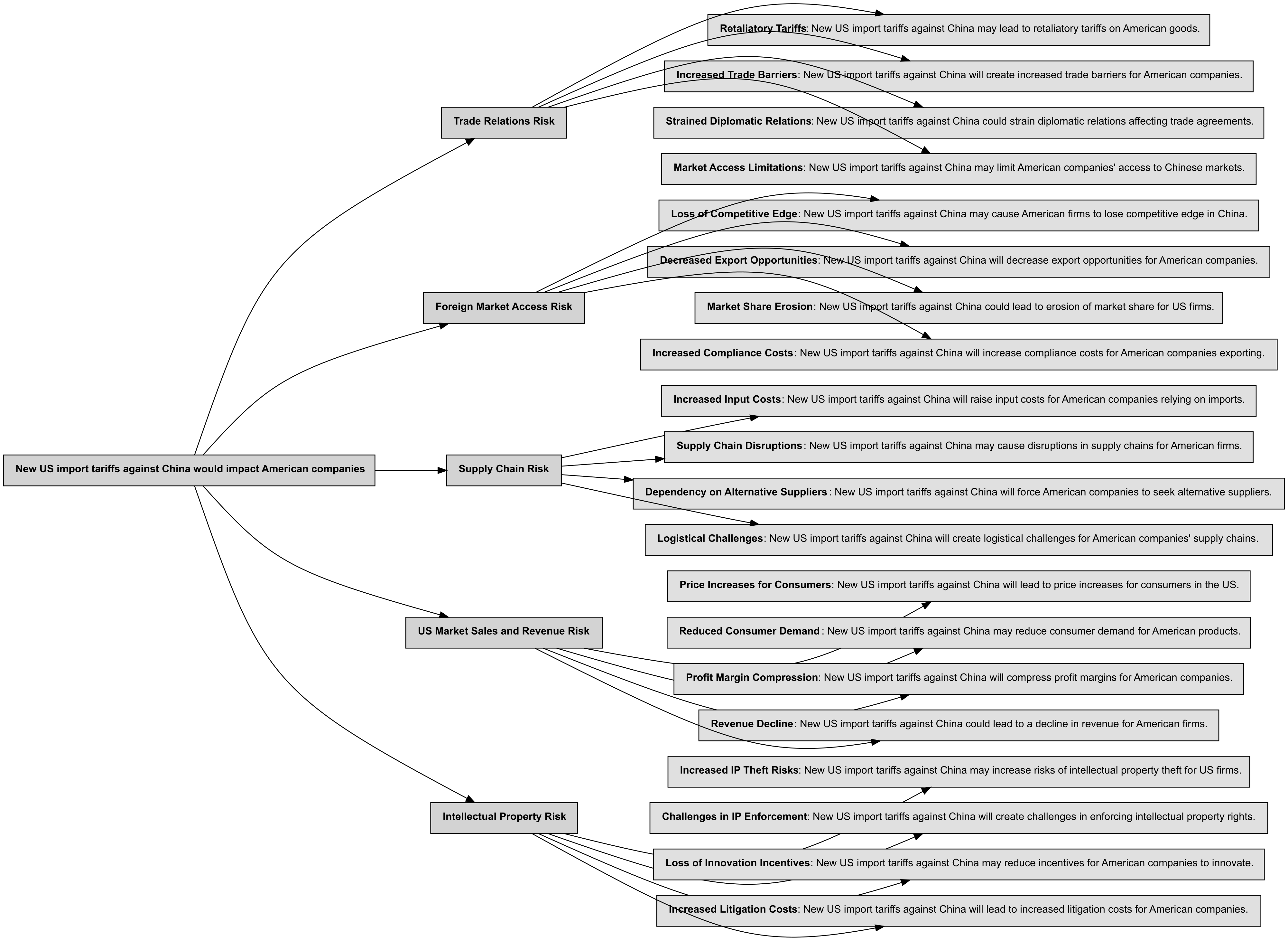
Retrieve Content
With the risk taxonomy and screening parameters, you can leverage the Search functionalities in bigdata-research-tools, built with Bigdata API, to run search at scale on your portfolio against news documents. We need to define 3 more parameters for searching:- Frequency (
freq): The frequency of the date ranges to search over. Supported values:Y: Yearly intervalsM: Monthly intervalsW: Weekly intervalsD: Daily intervals.
- Document Limit (
document_limit): The maximum number of documents to return per query to Bigdata API - Batch Size (
batch_size): The number of entities to include in a single batched query
Label the Results
Use an LLM to analyze each text chunk and determine its relevance to the sub-scenario. Any chunks which aren’t explicitly linking the companies mentioned to the risk sub-scenarios will be filtered out.Assess Risk Exposure
We will look at the most exposed companies to the risks stemming from new U.S. import tariffs against China. The functiongenerate_results will calculate the composite score, summing up the scores across the sub-scenarios for each company (df_company) or industry (df_industry) and add a global motivation statement (df_motivation).
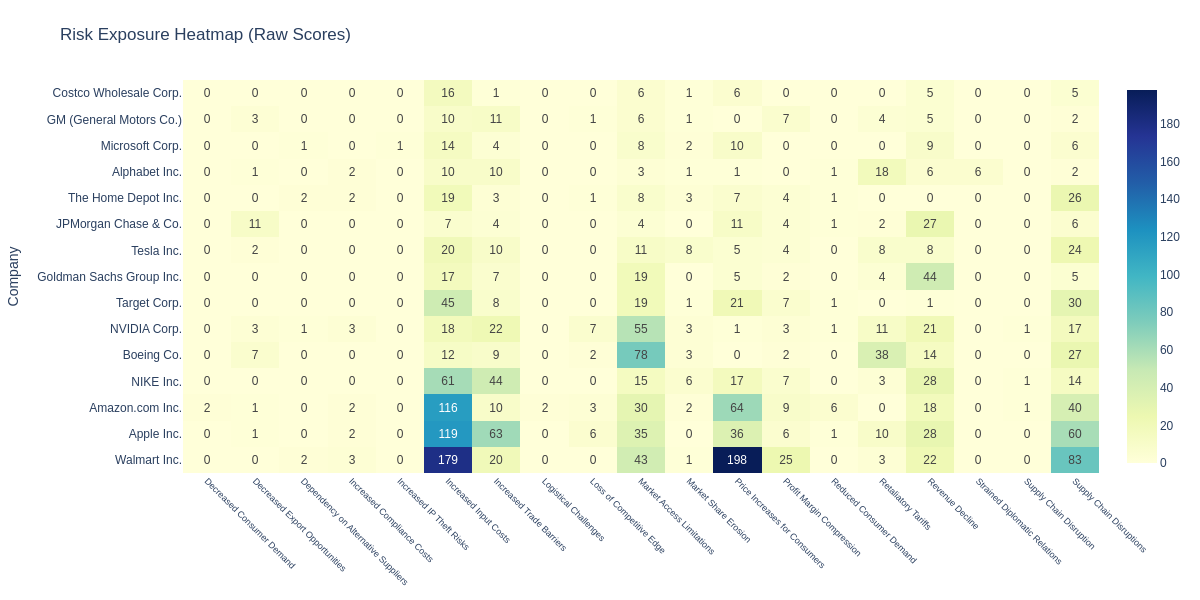
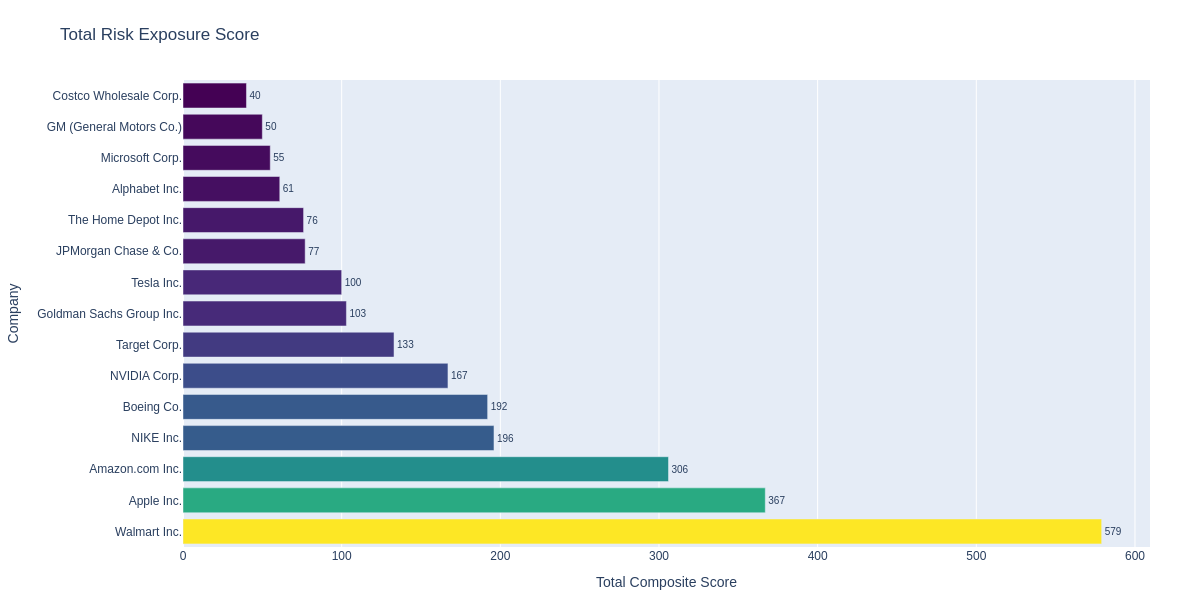
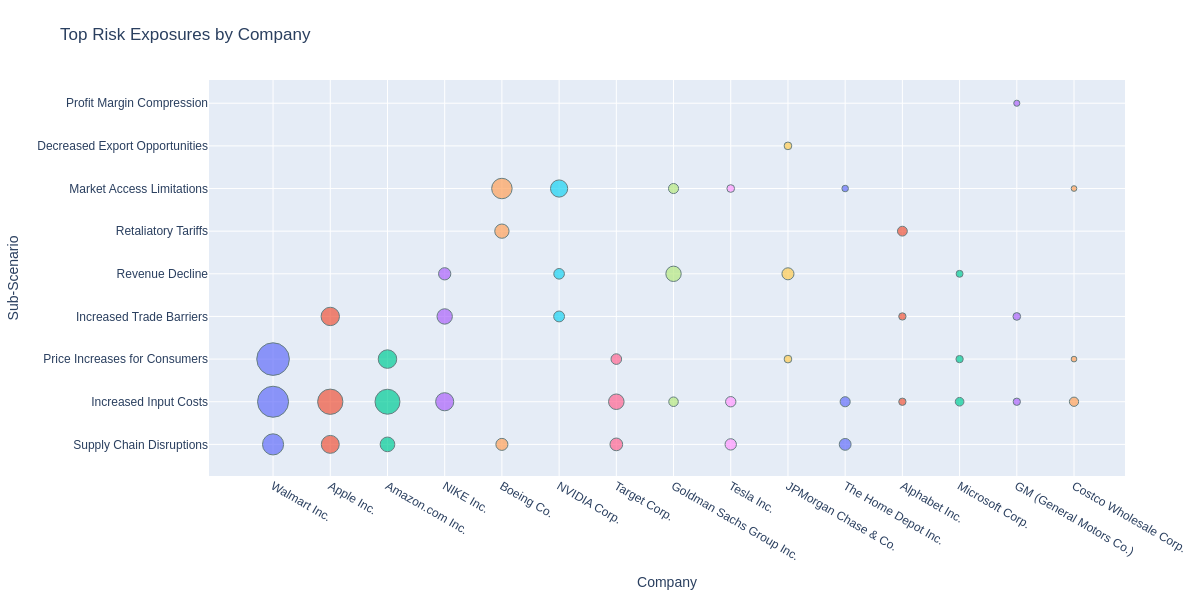
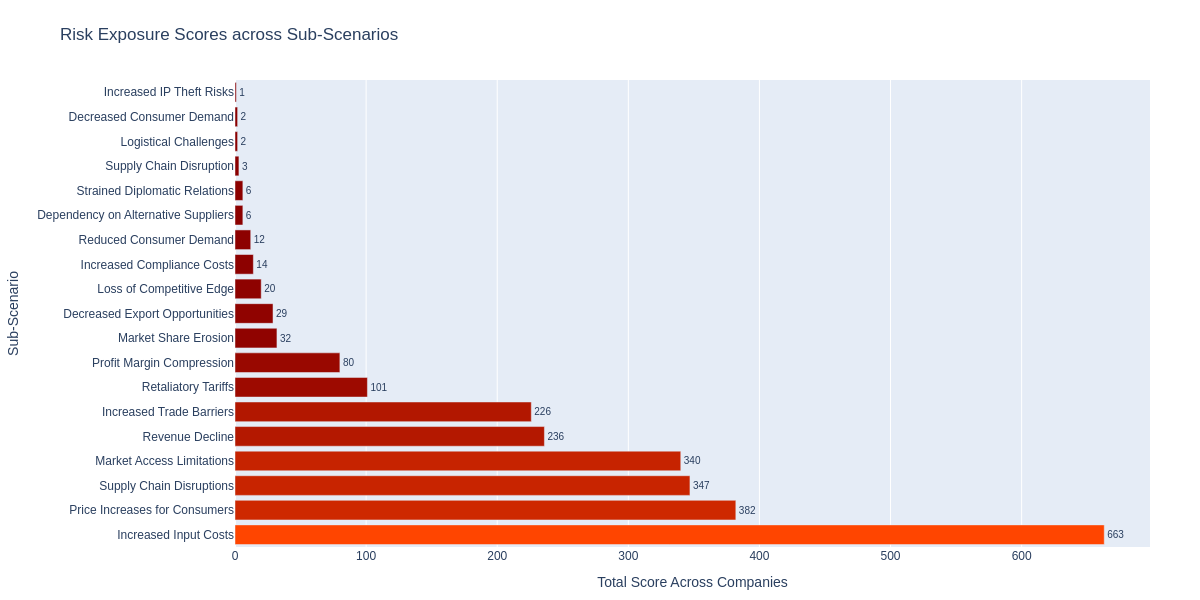
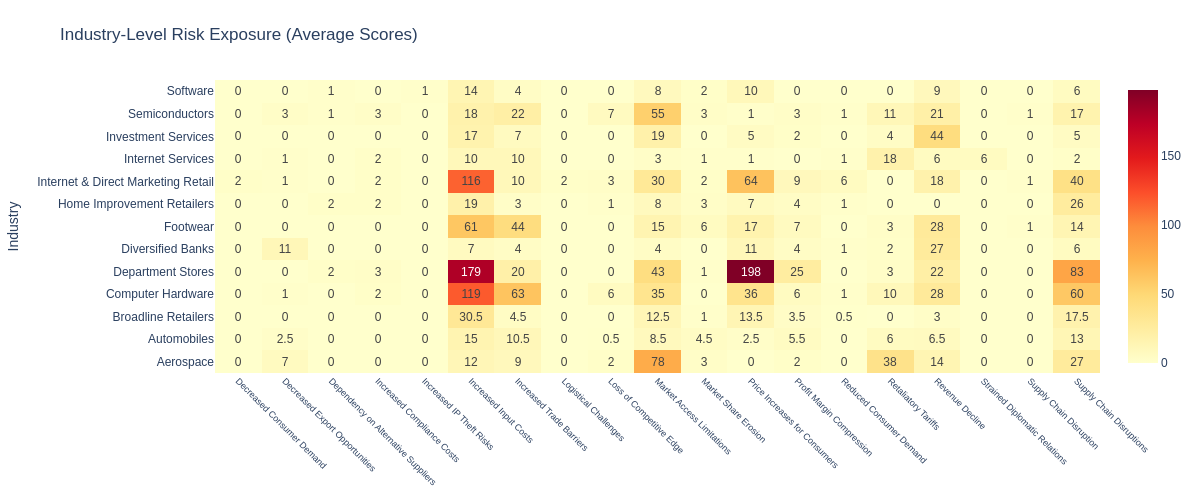
Extract Key Insights
The analysis reveals key insights about corporate exposure to U.S. import tariffs against China:Supply Chain Dependencies Drive Exposure
Companies with heavy reliance on Chinese manufacturing and supply chains show the highest exposure scores, indicating vulnerability to cost increases and operational disruptions from new tariff policies.
Technology Sector Shows Concentrated Risk
Technology companies demonstrate significant exposure due to their dependence on Chinese semiconductor and component manufacturing, with potential impacts on both costs and market access.
Consumer Goods Face Price Pressure
Consumer-facing companies show exposure through potential margin compression as they navigate between absorbing tariff costs and passing them on to customers.
Strategic Positioning Varies Widely
Companies with diversified supply chains and domestic alternatives show lower risk scores, highlighting the importance of supply chain resilience strategies.
Industry Risk Patterns
High-Risk Sectors
- Technology and Semiconductors show the highest average exposure due to supply chain concentration in China
- Consumer Discretionary companies face significant margin pressure from potential tariff costs
- Industrial Manufacturing with Chinese operations face operational complexity increases
Strategic Responses
- Companies with supply chain diversification strategies show lower risk scores
- Firms with domestic manufacturing capabilities demonstrate greater resilience
- Organizations with flexible sourcing strategies appear better positioned to navigate tariff impacts
Export the Results
Export the data as Excel files for further analysis or to share with the team.Conclusion
The Risk Analyzer provides a comprehensive framework for identifying and quantifying corporate exposure to specific risk scenarios. By leveraging advanced information retrieval and LLM-powered analysis, this workflow transforms unstructured data into actionable risk intelligence. Through the automated analysis of U.S. import tariff exposure, you can:- Identify vulnerable companies - Discover which firms in your portfolio face the highest exposure to tariff-related risks through their operational dependencies and market positions
- Compare across industries - Understand how different sectors are affected by trade policy changes, enabling sector-level hedging and diversification strategies
- Monitor risk evolution - Track how company exposure changes over time as they adapt their strategies or as policy developments unfold
- Generate investment insights - Use risk exposure scores to inform position sizing, hedging decisions, and portfolio construction in volatile geopolitical environments
- Support risk management - Provide quantitative backing for risk committee discussions and regulatory reporting requirements
- Consider underweighting companies with high exposure scores in anticipation of tariff implementation
- Use sector-level exposure analysis to guide allocation decisions and hedging strategies
- Monitor risk score changes to identify companies successfully adapting to trade policy challenges