March 23, 2026
Search, Diversification/8 minutes read
If you look at the current landscape of AI search APIs, most are heavily optimized for one metric: semantic and/or lexical relevance. But in the real world of enterprise and financial research, optimizing strictly for these introduces an unintended consequence: contextual homogeneity. When naïve relevance scoring dictates the top results, retrieved text chunks tend to cluster around a few sources or repeatedly surface the exact same angle on a story. For AI agents and RAG pipelines relying on these top 20 chunks to generate answers, this “monopolization” restricts perspective, creates redundant context processing, and wastes valuable LLM tokens on overlapping information.
At bigdata.com we use a multidimensional search system that does not only look at textual similarity. It looks at entity grounding, source authority, freshness, between others, and computes relevance taking into account all those factors. These factors improve the accuracy and quality of the results, but do not directly address the contextual homogeneity problem. In fact, sometimes it can cause more homogeneity, for example by focusing too strictly on the top authoritative sources. A classic engineering trade-off we had to solve: boosting premium tier-1 publishers sometimes collapsed the diversity.
Today, we are thrilled to announce a major upgrade to the bigdata.com API: Diversified Search. Diversified Search intelligently balances results across a wider array of premium sources and distinct viewpoints at the exact moment of retrieval. It preserves high-authority prominence while actively eliminating both single-source bias and semantically redundant information.
While traditional consumer search engines have probably spent a lot of time refining complex, proprietary diversification algorithms, the current ecosystem of AI-native search APIs often lacks this depth at the retrieval layer. Instead of building variety into the core retrieval algorithm, many modern AI search providers attempt to solve the problem by “brute-forcing” it. They automate the generation of multiple sub-queries to explore a topic from different angles, for example, generating 3 to 5 distinct query variations and running them in parallel.
This is a perfectly valid technique for expanding recall, but it is fundamentally not the optimal tool for achieving true variety. Not only increases latency and compute cost, but it is really not addressing the homogeneity problem and parallel query variations often end up retrieving very similar content.
At bigdata.com, we believe that baseline retrieval itself must be inherently diverse. You shouldn’t have to run multiple queries just to get a balanced set of results. This is why we build diversification in the core of our search.
Diversification in Action
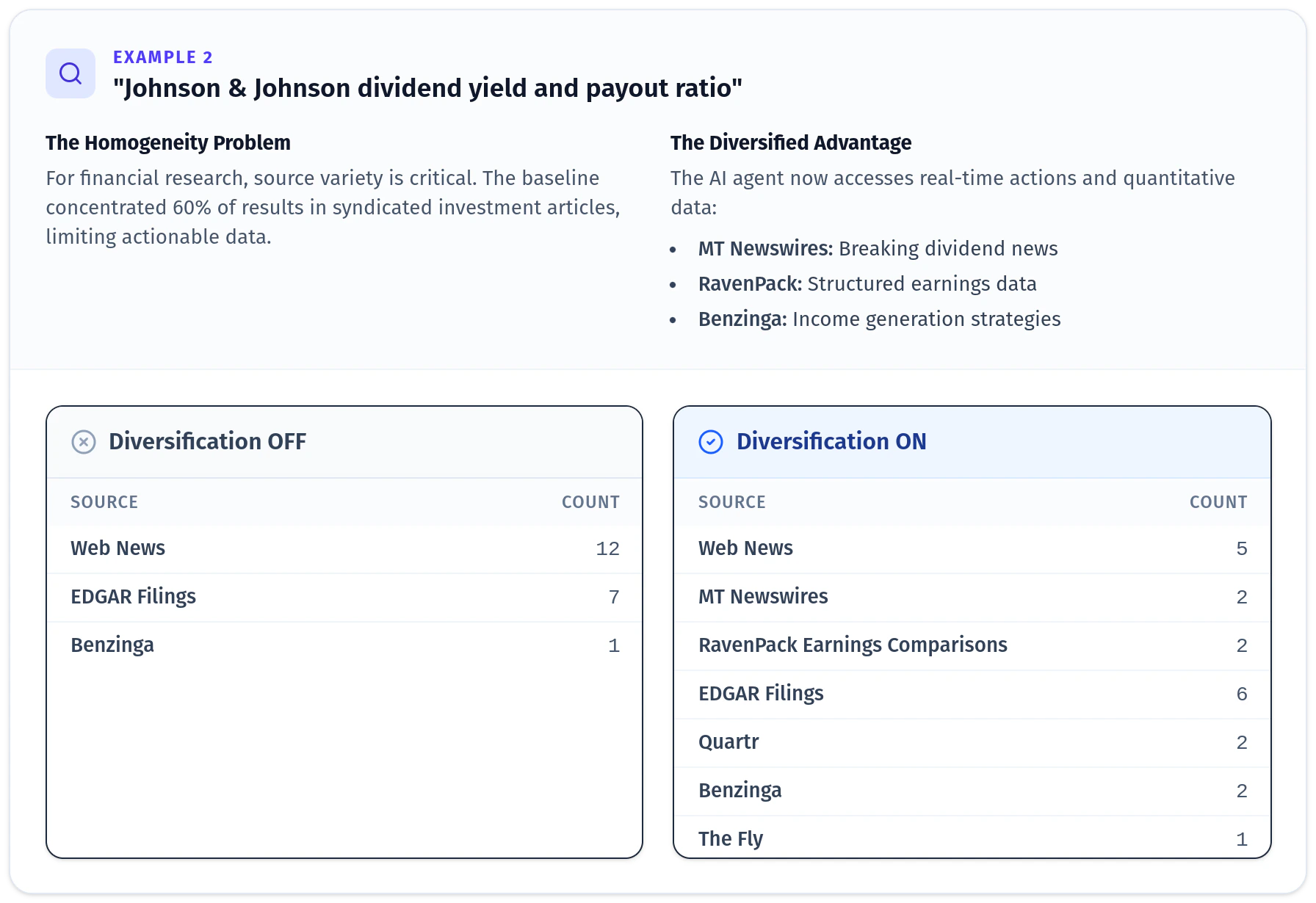
To illustrate the practical impact, let’s look at a couple real queries from our evaluation where diversification made a dramatic difference.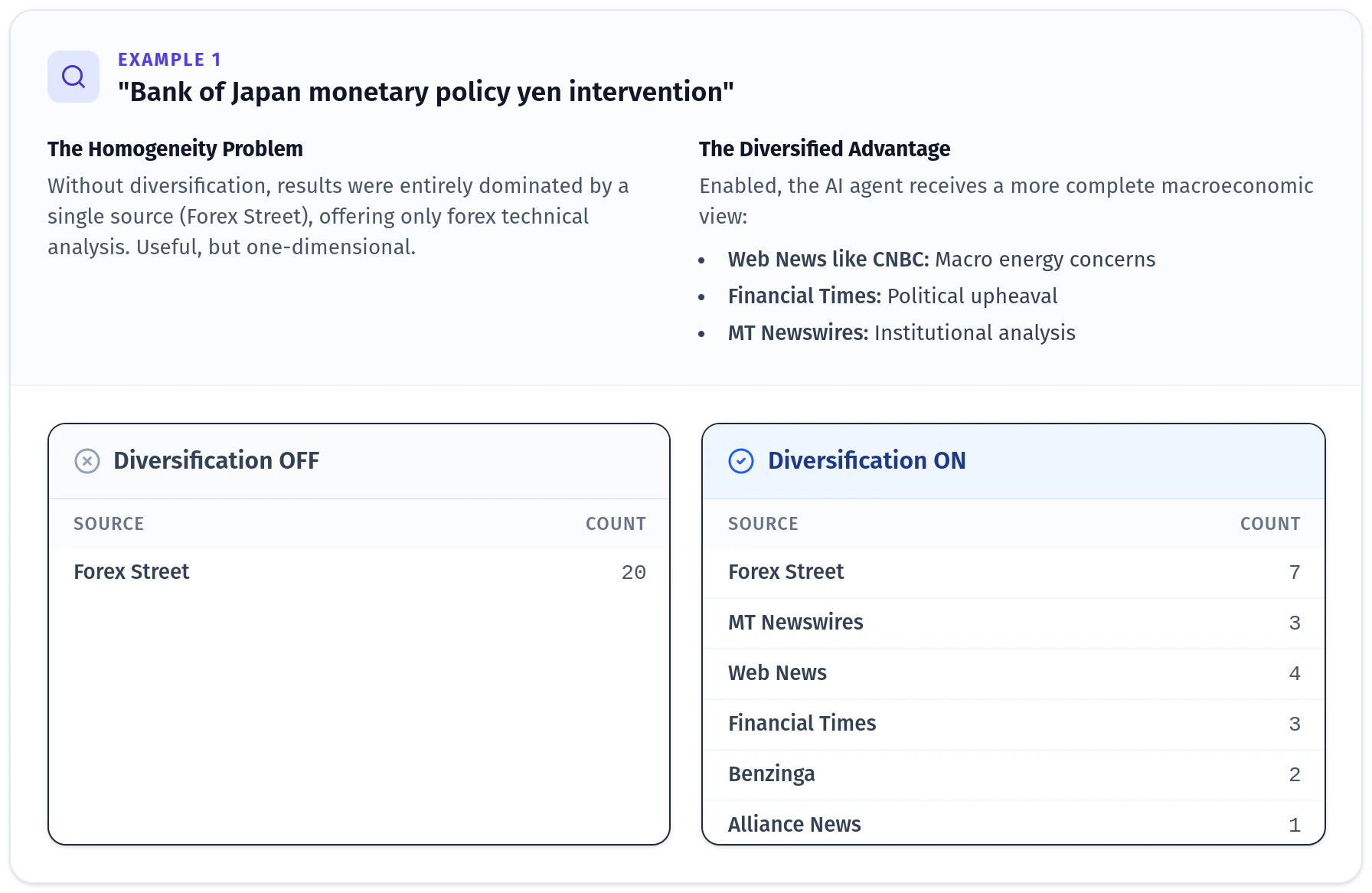
What’s Happening Under the Hood?
Building a search engine that understands both relevance and variety natively requires a sophisticated pipeline. The diagram below represents the additional steps that diversified search (right) performs when compared to the normal search process (left).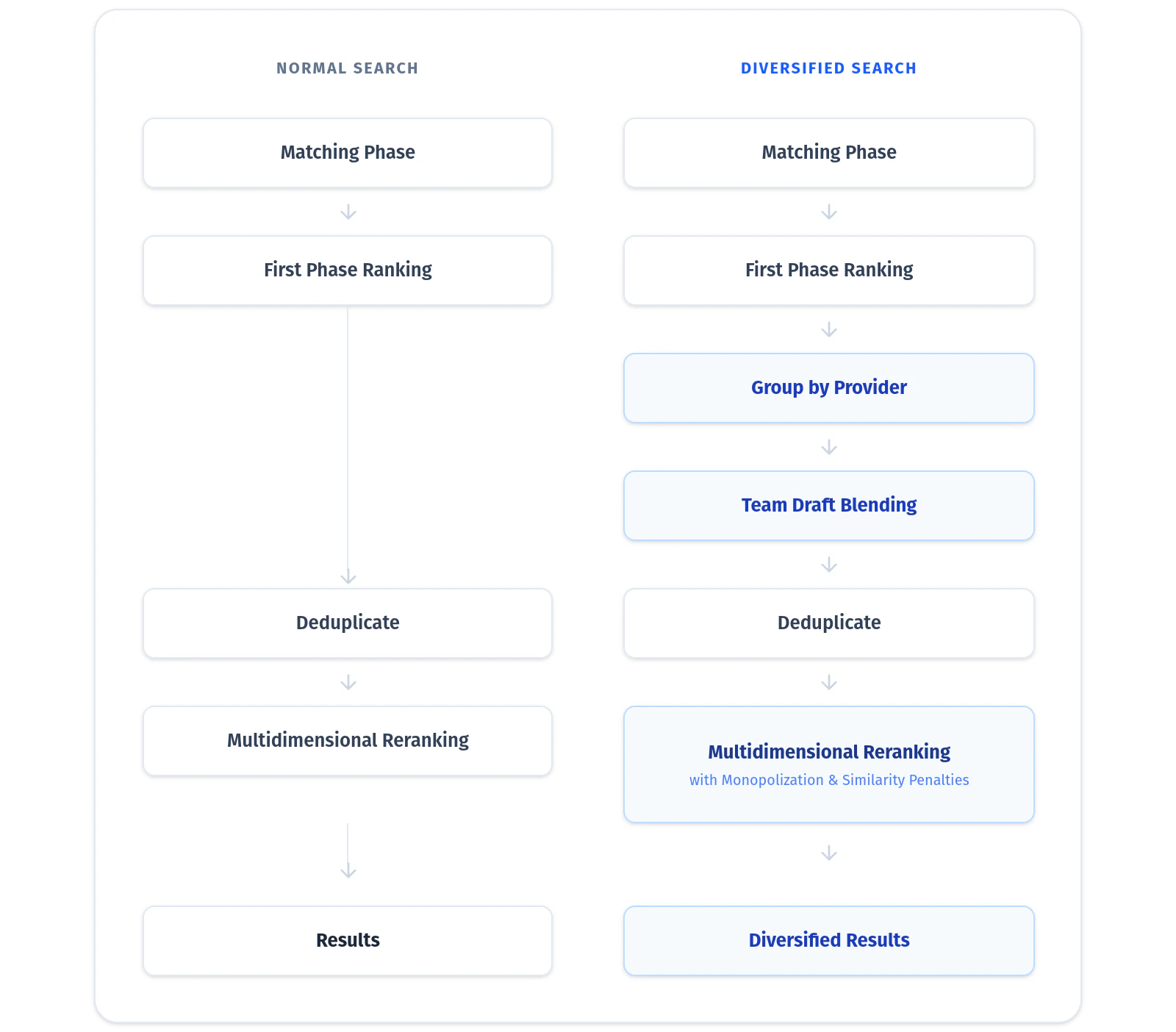
Ranking Phase with Source Grouping
Selected candidate results are initially grouped by content sources, after first phase ranking.Controlled Relevance Decay
These grouped candidates are blended using a controlled “team-draft” style selection process, forcing a decay in relevance scoring for subsequent chunks from the same sources to prevent top-slot domination.Embedding Deduplication
We reduce the pool of candidates and remove near-duplicates using dense embeddings.Reranking with Diversification Penalties
The final top chunk selection algorithm integrates the multidimensional reranking (cross-encoder fused with other factors such as freshness and source authority) while actively penalizing redundant content and single-source clustering. The result is a highly curated, deeply relevant, and broadly informative context window for your AI, delivered instantly.The Data: Diversification ON vs. OFF
To measure the exact impact of this feature, we ran a comparative evaluation using hundreds of queries, evaluating the Top 20 retrieved chunks with Diversified Search turned OFF (Baseline) versus ON. The results show a significant improvement in breadth without sacrificing quality or speed:| Metric | Result |
|---|---|
| Unique Sources | +40% increase — the specific origins of the content are significantly more varied |
| Content Similarity | Decreased — we observe a decrease in average chunk-to-chunk similarity (measured via both semantic and lexical overlap). Your LLM is fed more distinct information with every token, rather than paraphrased repetitions |
| Source Quality | Zero drop — the average Source Authority Rank remained stable. Premium, Tier-1 financial sources still surface to the top; they just don’t flood the results |
| Latency | Zero impact — our native diversification happens with no meaningful impact on response times |
How to Start Using It
Diversification allows us to shape a higher-quality result set, preserving strong relevance while drastically improving balance, authority, and perspective. It is available right now for all API users and enabled by default in both Fast Mode and Smart Mode. No changes to your existing API calls are needed — you will automatically benefit from diversified results. If you need the previous non-diversified behavior for a specific use case, you can opt out by setting the parameter explicitly:Sandra Bullón
Senior Product Manager
Ricard Matas Navarro
Director of Search & Retrieval (SVP)