May 5, 2026
Search, Web Search, External Search/10 minutes read
One API for premium financial content, the live web, and your own data
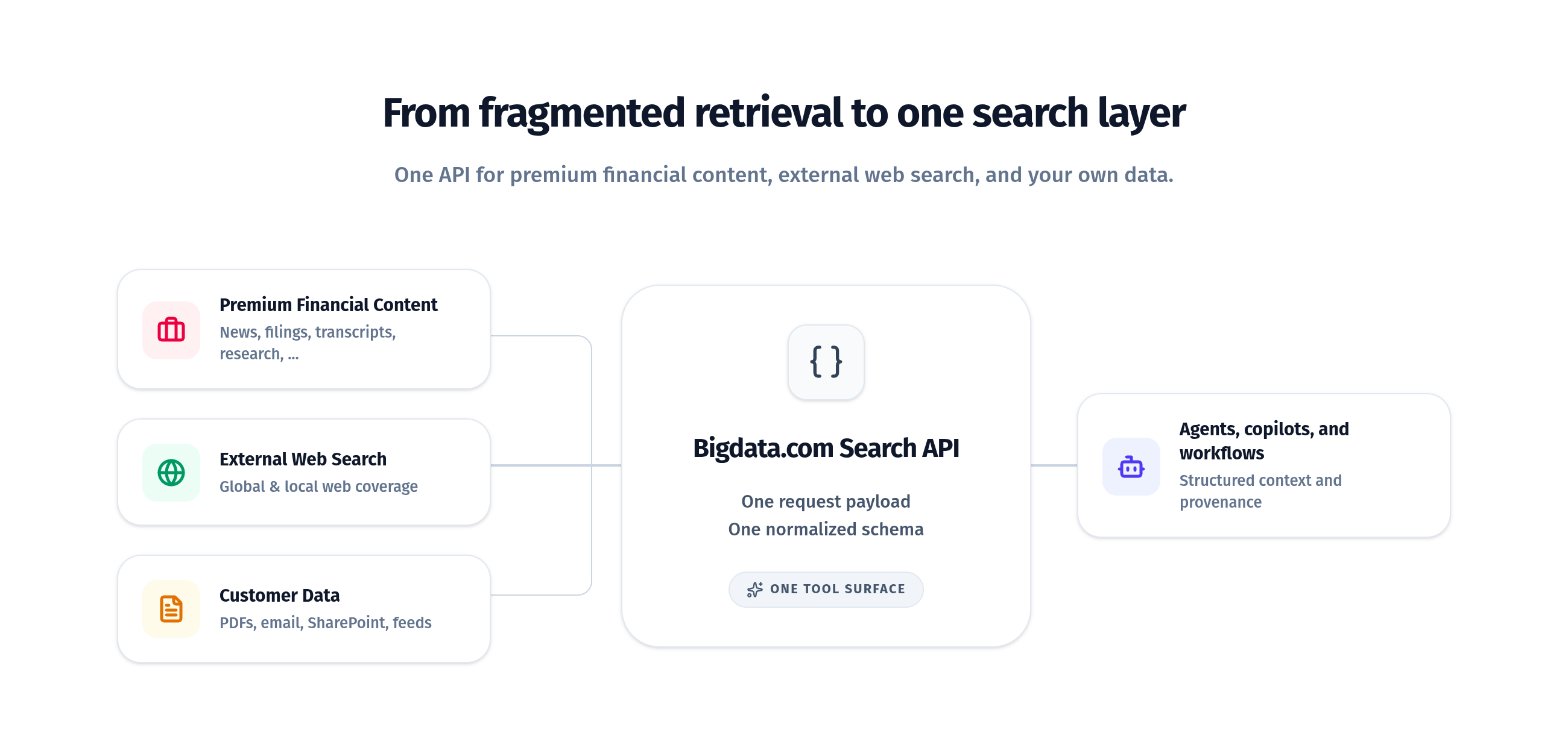
Why use Bigdata.com?
Broader coverage in one call
Bigdata.com already provides access to high-quality financial content across news, filings, transcripts, podcasts, expert interviews, investment research, and more. Developers can also bring their own content into the same environment by uploading files such as PDFs or connecting feeds such as email and Sharepoint. Web Search adds live web results to that system. The result is broader coverage across complementary sources in one call, without forcing developers to stitch them together themselves. This release is part of a larger direction for Bigdata.com: one platform that keeps getting broader with all types of content, soon also with live social signals as well.One schema across sources
Whether content comes from Bigdata.com’s premium corpus, the live web, or customer-provided data, the API returns a consistent structure. That reduces application-side normalization, simplifies ranking and post-processing, and makes it easier to build stable downstream workflows.Less orchestration, less token waste
Multiple search tools create hidden costs. Each one needs its own request payload, its own tool description, its own response parser, and its own merge logic. In LLM-powered systems, that means extra tokens spent on tool selection and output reconciliation before the model even starts doing the real work. With Bigdata.com, developers can expose one retrieval surface instead of several. That makes downstream applications simpler, more predictable, and more efficient in how they use context. Moreover, when models have to choose across multiple retrieval tools, they can misfire: calling the wrong tool, over-calling several tools, or handling sources inconsistently because each provider behaves differently. A single API surface reduces that operational ambiguity. Developers still get access to multiple underlying sources, but the application and the model interact with one consistent interface.One commercial relationship
Adding live web coverage through Bigdata.com means teams can expand retrieval without standing up a separate vendor evaluation, new security review, or another billing path. That matters in production just as much as it does in prototyping.Clear provenance
Bigdata.com Web Search is opt-in. Existing queries stay unchanged unless web is enabled explicitly in the external search. And live web results are returned separately inexternal_results.web, so applications can preserve strict provenance while still working with a normalized schema.
Complementary coverage matters
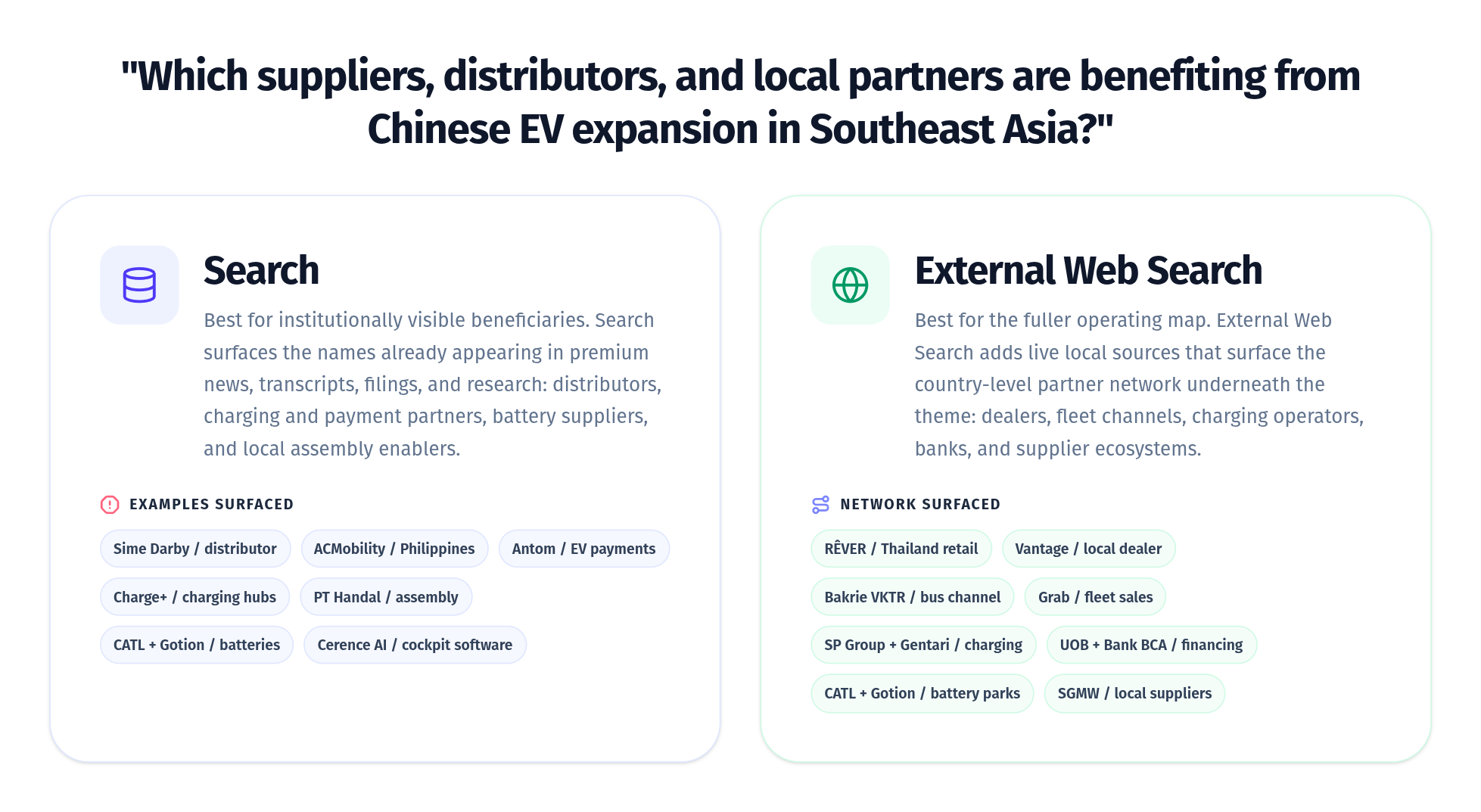
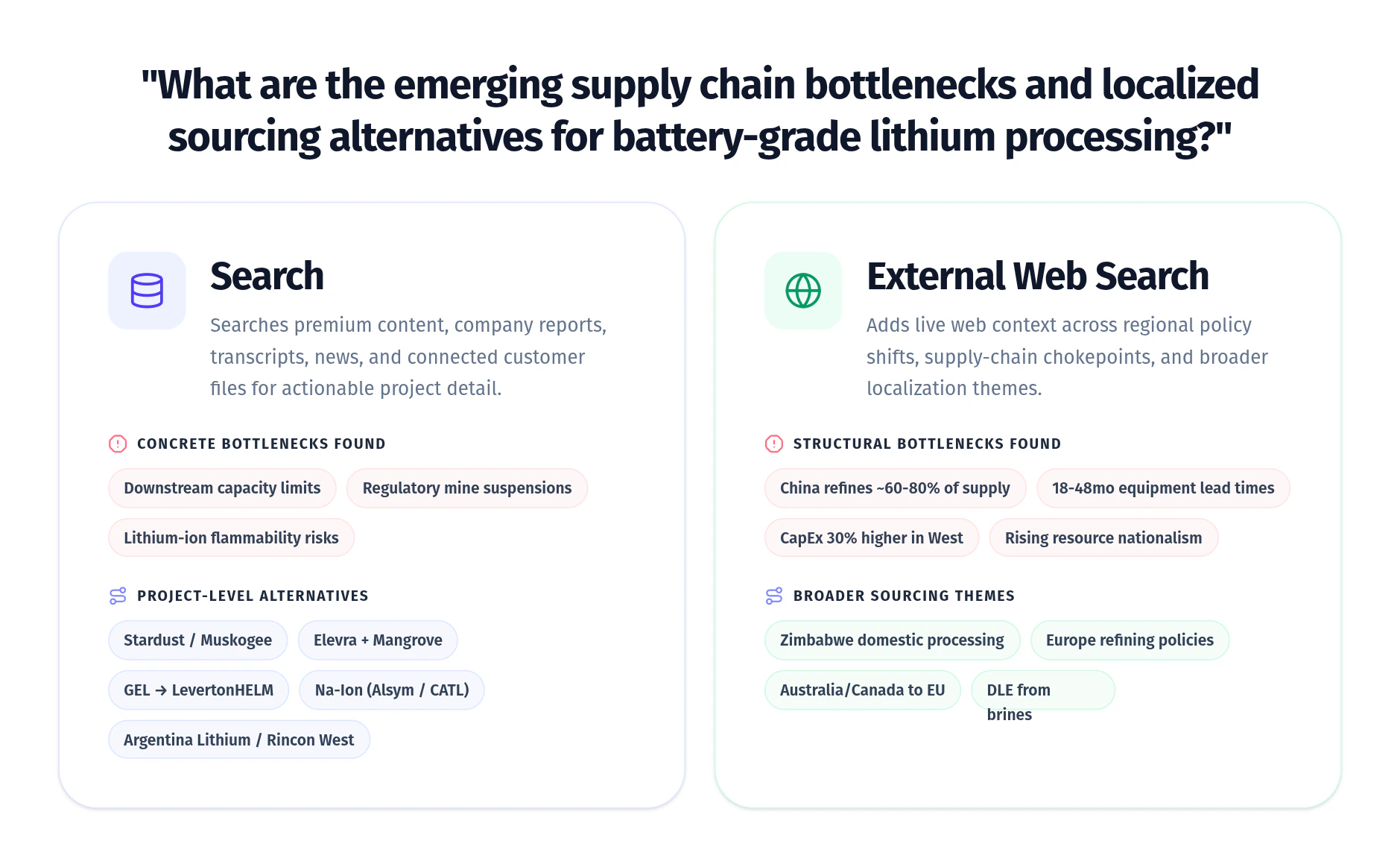
Premium financial content and live web search are not interchangeable. They often contribute different kinds of signal. Bigdata.com’s premium corpus is strongest on decision-grade financial content: filings, transcripts, structured disclosures, institutional research, expert interviews, financial events and major news. Live web search is strongest on long-tail coverage: company websites, scientific and technical pages, regional reporting, niche publications, and early-stage company footprints. Especially useful for very early-stage companies with no analyst coverage. Used together, they widen the context available to downstream applications. Premium content explains how the market interprets a company or theme. The web shows what companies are publishing, building, testing, and updating in real time. The examples below show how the two sources work together in practice:
Built for real-world financial workflows
This matters beyond search. Financial applications increasingly combine external intelligence with customer-owned context. A team may want to search public market information alongside internal PDFs, research memos, email threads, or other proprietary documents. Bigdata.com already supports that model today: developers can retrieve across premium content, live web content, and customer-provided data in the same environment. That makes it easier to build research assistants, diligence workflows, monitoring systems, and agentic applications that need to reason across both public and private information.How to use it
Bigdata.com Web Search is designed to be explicit and easy to control. Addweb to the external_search payload object, either in ONLY or in INCLUDE mode, to get results only from external search or from inclusive to any other content you selected for the internal search in the payload.
external_results.web:
Transparent pricing
Web search is a separately billable capability, tracked separately in the usage dashboard, and is only charged when explicitly invoked.| Component | Example pricing | When it applies |
|---|---|---|
| Search | $0.015 per 10 chunks of internal data | Standard processing fee |
| External Search, Web | +$0.02 per request for up to 20 chunks of data | Only when external_search.values → web is enabled |
What’s next
We’re already working on extending the same enrichment pipeline we use for premium content to open-web results. In upcoming releases, web search documents will be annotated with entity detections, mapped to our universal IDs and additional metadata such as real-time sentiment, making live web content easier to use inside research workflows, analytics pipelines, and LLM applications. We’re also working on live social search, with X and Reddit coming next. Over time, Bigdata.com will continue adding more content APIs and connectors, so developers can access premium financial content, live web coverage, customer-owned data, and live social signals through one platform instead of a growing patchwork of tools.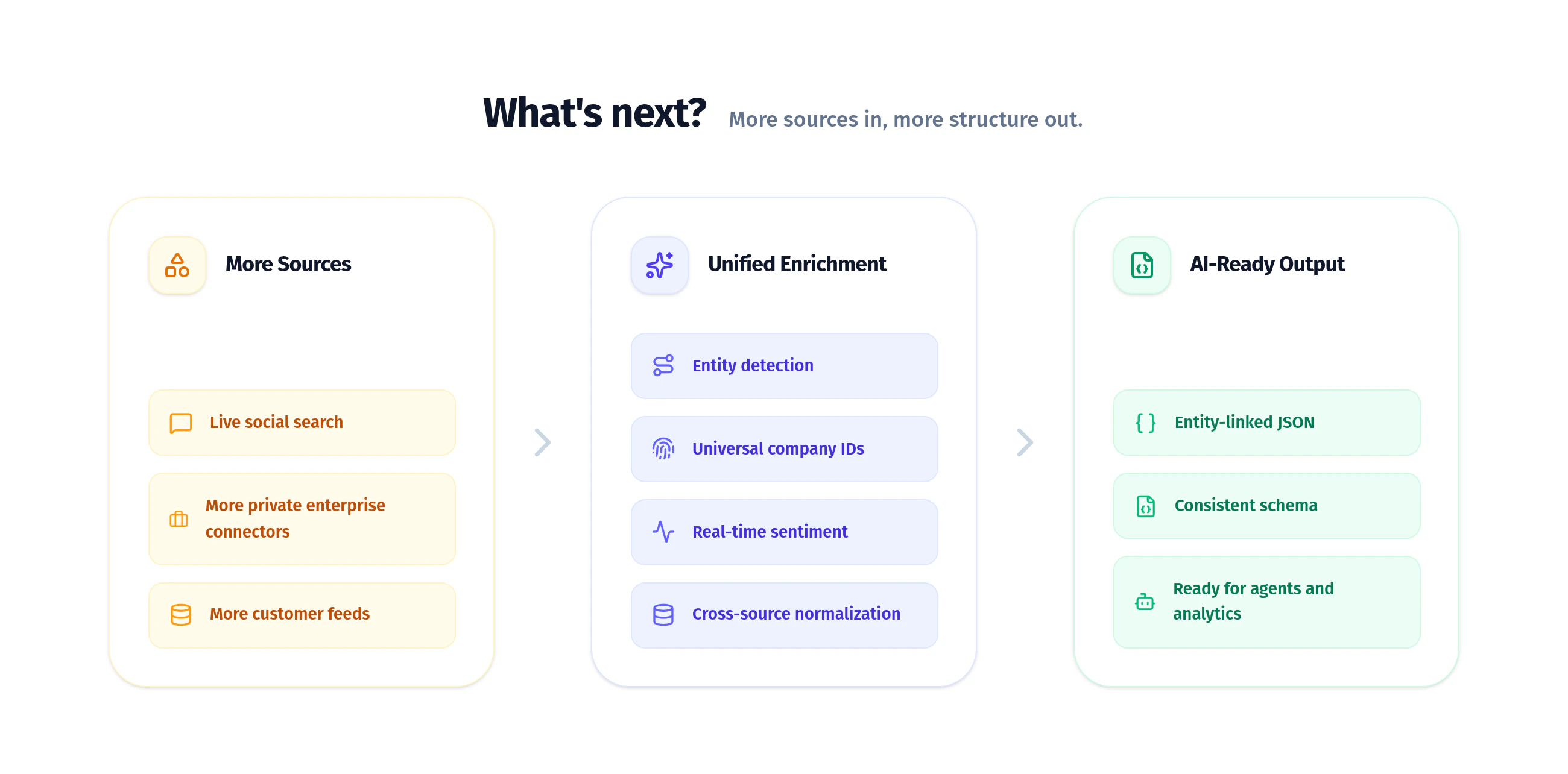
Available now
Web Search is available today in the Bigdata.com Search API. Addweb inside external_search.values to retrieve live web content alongside Bigdata.com’s financial content and your own data — through one API, one schema, and one growing content layer for financial AI.
Ricard Matas Navarro
Director of Search & Retrieval (SVP)