Why It Matters
Thematic investing requires systematic identification of companies aligned with structural trends, but manually tracking exposure across thousands of documents is inefficient and inconsistent. As mega-trends like AI and decarbonization reshape markets, investors need scalable ways to quantify which companies are genuinely positioned to benefit.What It Does
TheThematicScreener class in the bigdata-research-tools package helps solve this problem. Designed for analysts, PMs, and strategists managing thematic portfolios or scouting new ideas, it systematically connects companies to investment themes using unstructured data from news, earnings calls, and filings.
How It Works
TheThematicScreener combines LLM-powered theme taxonomies, semantic content retrieval, and structured scoring methodologies to deliver:
- Automated theme breakdown into specific, measurable sub-categories
- Systematic positioning analysis to identify how companies align with key themes
- Cross-sector exposure comparison enabling portfolio-level thematic assessment
- Qualitative-to-quantitative transformation that turns narrative signals into structured, actionable insights
A Real-World Use Case
This cookbook walks through a full workflow, from defining a theme to quantifying company exposure, using “Supply Chain Reshaping” analysis across Top US 100 companies as a practical example. Ready to get started? Let’s dive in!Prerequisites
To run the Thematic Screener workflow, you can choose between three options:-
▶️ Colab cookbook
- Use this if you prefer running the workflow in a cloud environment.
- Follow the instructions written directly inside the cookbook.
- API keys must be configured as described within the Colab file itself.
-
💻 GitHub cookbook
- Use this if you prefer working locally or in a custom environment.
- Follow the setup and execution instructions in the
README.md. - API keys are required:
- Option 1: Follow the key setup process described in the
README.md - Option 2: Refer to this guide: How to initialise environment variables
- ❗ When using this method, you must manually add the OpenAI API key:
- ❗ When using this method, you must manually add the OpenAI API key:
- Option 1: Follow the key setup process described in the
-
🐳 Docker Installation
- Docker installation is available for containerized deployment.
- Provides an alternative setup method with containerized deployment, simplifying the environment configuration for those preferring Docker-based solutions.
Setup and Imports
Below is the Python code required for setting up our environment and importing necessary libraries.Defining your Screening Parameters
- Main Theme (
main_theme): The central concept to explore - Company Universe (
companies): The set of companies to screen - Time Period (
start_dateandend_date): The date range over which to run the search - Document Type (
document_type): Specify which documents to search over (transcripts, filings, news) - Sources (
sources): Specify set of sources within a document type, for example which news outlets (available via Bigdata API) you wish to search over - Fiscal Year (
fiscal_year): If the document type is transcripts or filings, fiscal year needs to be specified - Model Selection (
llm_model): The LLM model used to mindmap the theme and label the search result chunks - Rerank Threshold (
rerank_threshold): By setting this value, you’re enabling the cross-encoder which reranks the results and selects those whose relevance is above the percentile you specify (0.7 being the 70th percentile). More information on the re-ranker can be found here. - Focus (
focus): Specify a focus within the main theme. This will then be used in building the LLM generated mindmapper
Mindmap a Theme Taxonomy with Bigdata Research Tools
You can leverage Bigdata Research Tools to generate a comprehensive theme taxonomy with an LLM, breaking down a megatrend into smaller, well-defined concepts for more targeted analysis.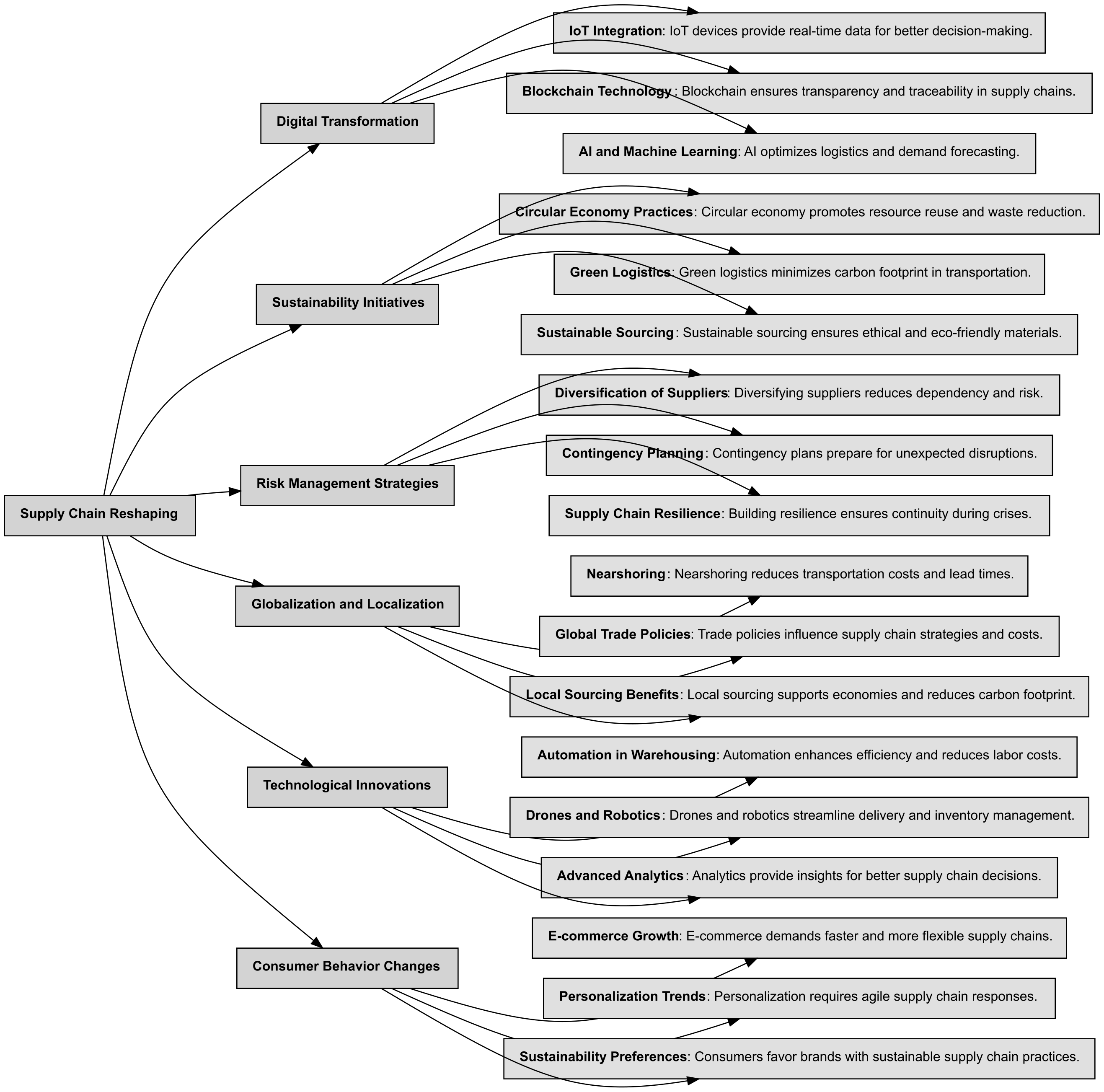
Retrieve Content
With the theme taxonomy and screening parameters, you can leverage the Bigdata API to run a search on company transcripts. We need to define 3 more parameters for searching:- Frequency (
freq): The frequency of the date ranges to search over. Supported values:Y: Yearly intervals.M: Monthly intervals.W: Weekly intervals.D: Daily intervals. Defaults to3M.
- Document Limit (
document_limit): The maximum number of documents to return per query to Bigdata API. - Batch Size (
batch_size): The number of entities to include in a single batched query.
Preview the DataFrame
Preview the DataFrame
Additional Columns: Masked Text, RP Entity ID, Entity Sector, Entity Industry, Entity Country, Entity Ticker, Other Entities, Entities, Other Entities Map
Label the Results
Use an LLM to analyze each text chunk and determine its relevance to the sub-themes. Any chunks which aren’t explicitly linked to supply chain reshaping will be filtered out.Assess Thematic Exposure
We’ll look at the top 10 most exposed companies to supply chain reshaping. The functionget_scored_df will calculate the composite thematic score, summing up the scores across the sub-themes for each company (df_company) or industry (df_industry).
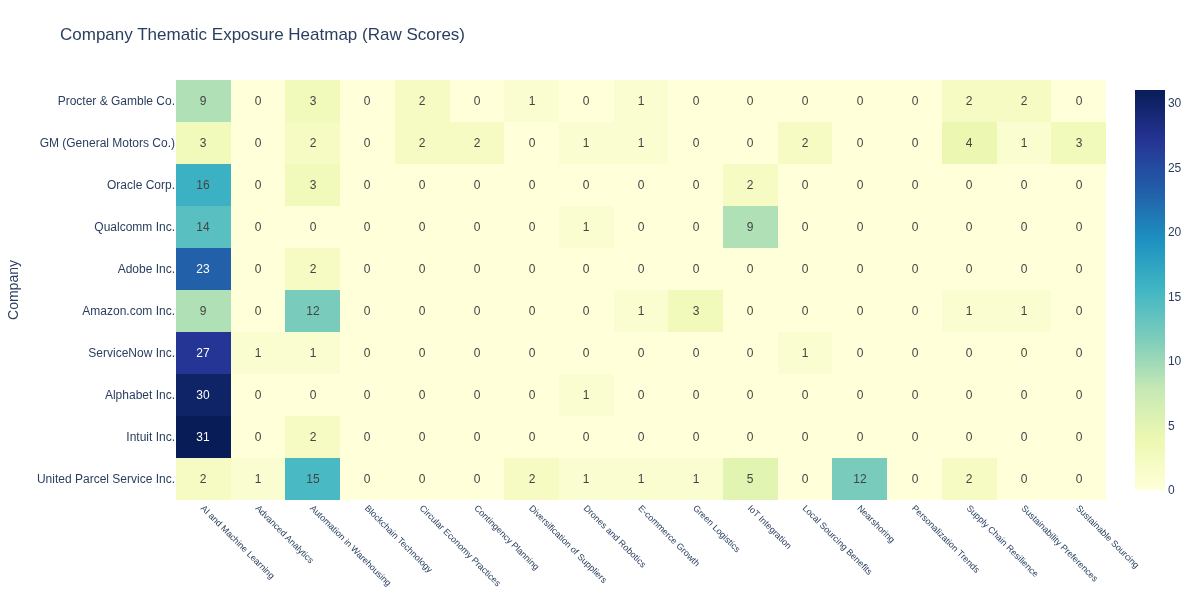
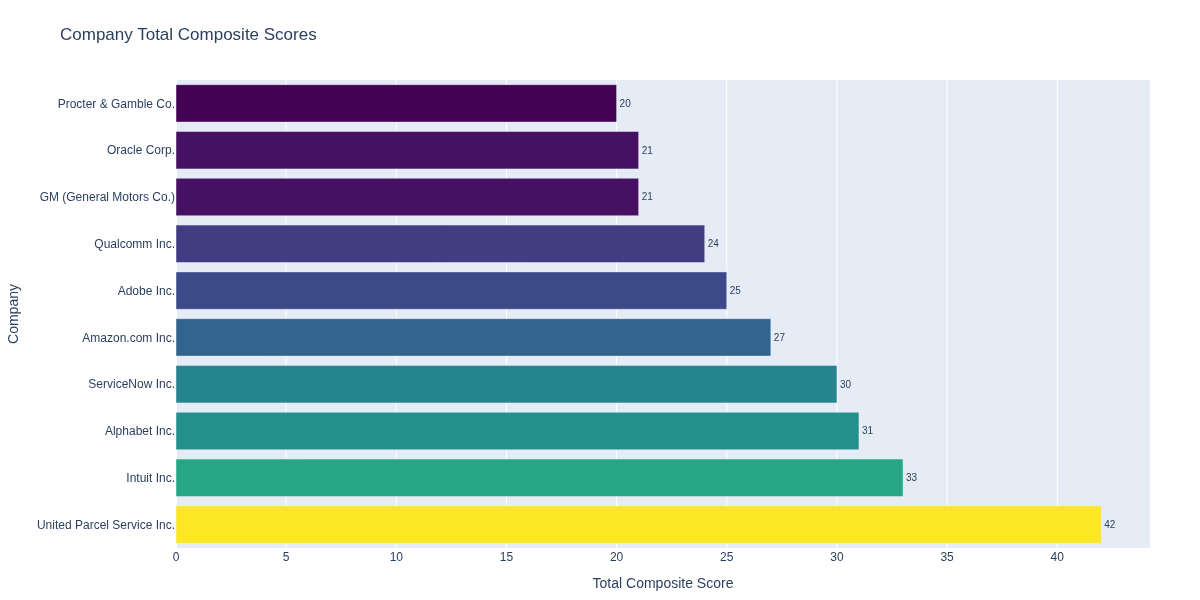
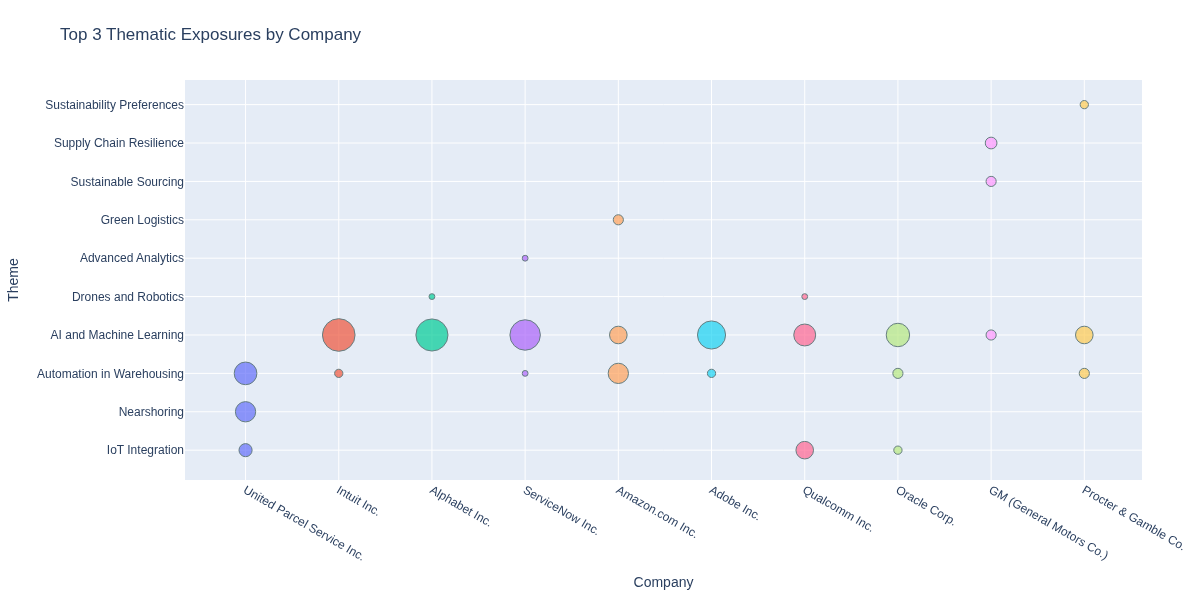
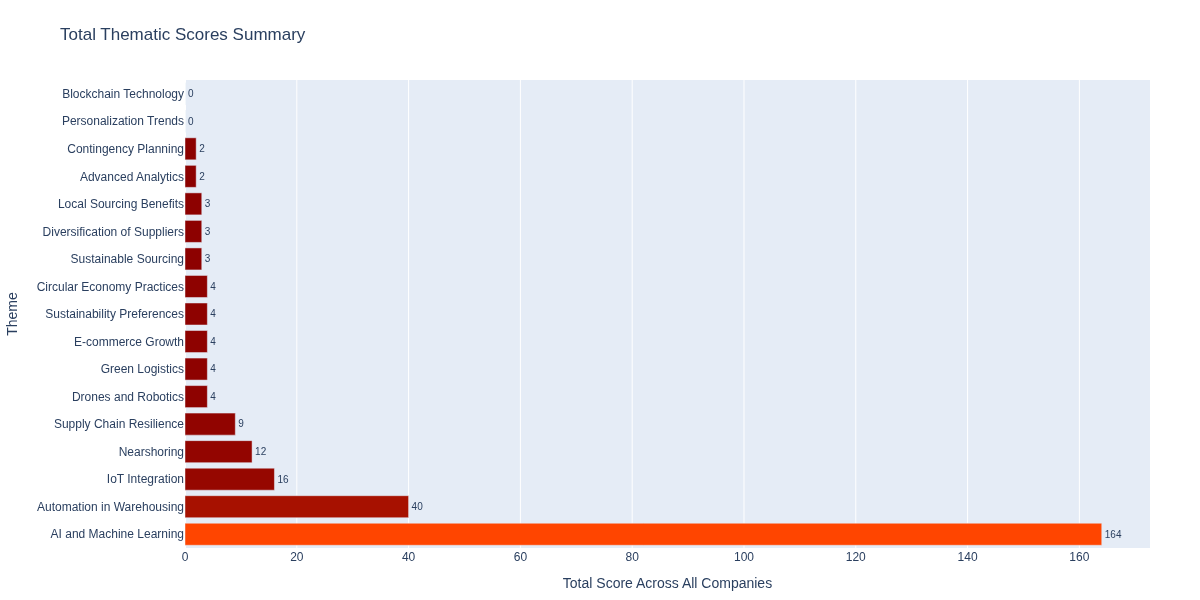
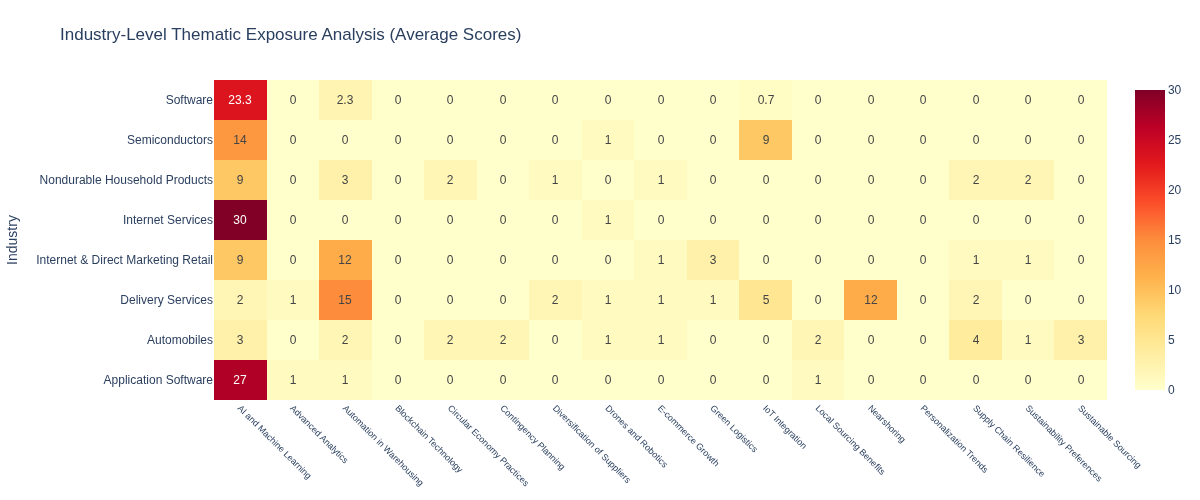
Extract Key Insights
The visualizations reveal key insights about how companies are positioning themselves within the supply chain reshaping theme:AI and Machine Learning Emerges as the Core Enabler
With the highest cumulative score across all companies, AI and Machine Learning is the most dominant theme, highlighting its foundational role in predictive analytics, automation, and optimization within modern supply chains.
Circular Economy and Automation as Structural Shifts
The strong presence of Circular Economy Practices and Automation & Robotics indicates a structural shift toward sustainable and efficient supply chain models—companies are not just digitizing but rethinking operational design.
Tech-Centric Players Lead the Pack
Siemens AG, Infineon Technologies AG, and Qualcomm Inc. are the frontrunners in thematic exposure, underscoring that companies at the intersection of industrial technology and digital infrastructure are best positioned to drive—and benefit from—supply chain transformation.
IoT Integration as a Bridge Between Physical and Digital
IoT’s high ranking shows its critical role in connecting assets, enabling real-time visibility, and facilitating advanced automation, especially for manufacturers and hardware-driven firms.
Industry Polarisation
Sector Engagement
- Semiconductors and Computer Services industries show the strongest average exposure, reflecting their integral role in enabling supply chain tech (e.g., sensors, connectivity, software).
- Traditional Sectors like Diversified Industrials show broader but shallower engagement, suggesting they are still in earlier phases of thematic adoption.
Strategic Focus
Concentration vs. Diversification in Exposure Most companies exhibit thematic concentration, focusing efforts on a few high-impact areas rather than spreading across all themes—likely reflecting strategic prioritization rather than lack of alignment.Export the Results
Export the data as Excel files for further analysis or to share with the team.Conclusion
The Thematic Screener provides a powerful way to identify companies that are most aligned with or exposed to specific investment themes. By leveraging BigData’s search capabilities and applying LLM-based classification, you can:- Discover thematic leaders - Find companies with the strongest strategic alignment to emerging trends
- Compare across industries - Identify which sectors are most proactive in addressing thematic challenges and opportunities
- Identify investment opportunities - Spot companies that may be undervalued relative to their thematic positioning
- Monitor thematic evolution - Track how themes gain or lose prominence across your investment universe over time