People entity to identify where and when an individual is mentioned across selected documents.
Why It Matters
Tracking specific individuals across news coverage is essential for governance analysis and investment decisions, but manually monitoring when and where these people are mentioned in thousands of articles is resource-intensive. This workflow leverages bigdata’s entity tracking capabilities to systematically monitor individuals, providing comprehensive analysis of their media exposure and reputation signals to identify potential risks and opportunities.What It Does
This Board Management Monitoring workflow systematically tracks specific individuals across news coverage using multiple search strategies. Built for analysts, portfolio managers, and investment professional, it transforms scattered mentions into structured intelligence about management activity and board dynamics.How It Works
The workflow combines multi-mode search strategies, entity-specific filtering, and temporal analysis to deliver:- Comprehensive person tracking across multiple name variations and contexts
- Company-specific filtering ensuring relevance to the monitored organization
- Multi-mode search precision from strict entity matching to broader coverage with post-filtering
- Source filtering enabling focused analysis across trusted news sources
- Temporal analysis showing how coverage patterns evolve over time
A Real-World Use Case
This workflow demonstrates monitoring Emmanuel Faber from Danone S.A., tracking his exposure across management integrity themes and board governance topics, showing how different search modes capture varying levels of coverage. Ready to get started? Let’s dive in!Prerequisites
To run the analysis, you can choose between two options:-
💻 GitHub cookbook
- Use this if you prefer working locally or in a custom environment.
- Follow the setup and execution instructions in the
README.md. - API keys are required:
- Option 1: Follow the key setup process described in the
README.md - Option 2: Refer to this guide: How to initialise environment variables
- ❗ When using this method, you must manually add the OpenAI API key:
- ❗ When using this method, you must manually add the OpenAI API key:
- Option 1: Follow the key setup process described in the
-
🐳 Docker Installation
- Docker installation is available for containerized deployment.
- Provides an alternative setup method with containerized deployment, simplifying the environment configuration for those preferring Docker-based solutions.
Setup and Imports
Below is the Python code required for setting up our environment and importing necessary libraries.Parameters Definition
Fixed Parameters
- First Theme (
management_themes): List of sentences about a theme you are interested in - Second Theme (
board_themes): List of sentences about a theme you are interested in - Dates (
date_periods): List of tuples containing starting and ending date of a specific period of time. The dates used in this workflow are chosen to provide adequate temporal coverage surrounding the earnings dates - Trusted Sources (
trusted_sources): Dictionary containing the sources and their ID - Person of interest (
persons_dict): Dictionary containing the name of the person to search for, their ID and their possible different ways of naming them - Company of interest (
company_name,company_id): The name of the company to search for and a dictionary with its ID - Search Mode (
search_mode): Different ways of searching for that specific personstrict: Company entity and person must appear at chunk levelrelaxed: Only person name variations are usedrelaxed_post: Person search with company filtering at document level
- Trusted Sources Flag (
use_trusted_sources): Flag to activate filtering with trusted sources
Search Mode Configuration
The workflow supports three different search modes, each offering different levels of precision and recall:Search Mode Options
- Strict Mode: Company entity and person must appear at chunk level - highest precision
- Relaxed Mode: Only person name variations are used - highest recall
- Relaxed Post Mode: Person search with company filtering at document level - balanced approach
Multi-Mode Monitoring Execution
The workflow executes all three search modes to provide comprehensive coverage analysis:Results Analysis and Visualization
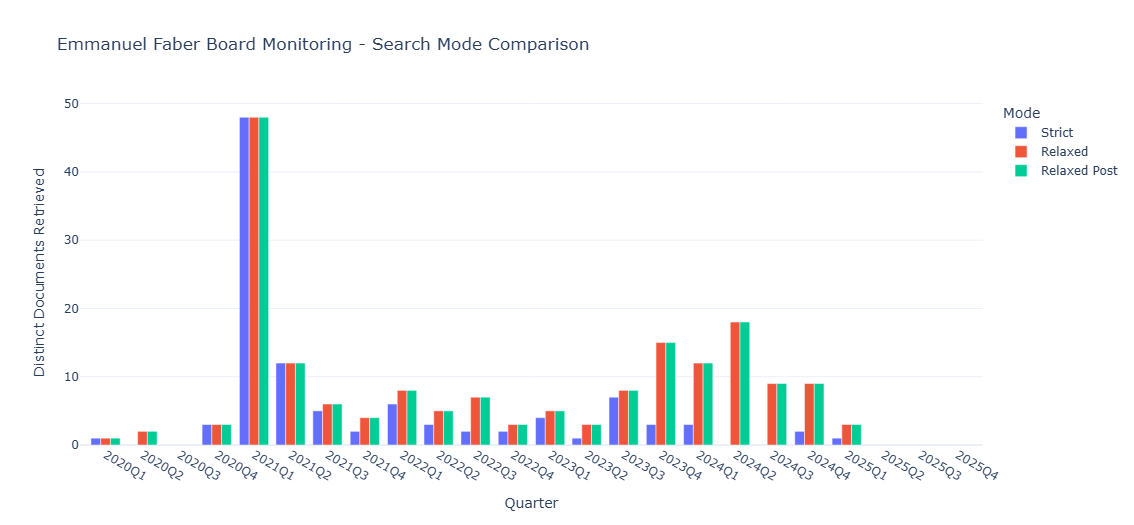
After executing all search modes, load and compare the results:Search Mode Comparison:
- Strict Mode: 97 documents
- Relaxed Mode: 172 documents
- Relaxed Post Mode: 172 documents
Quarterly Activity Visualization
Generate comprehensive quarterly analysis showing how coverage volume changes across time periods: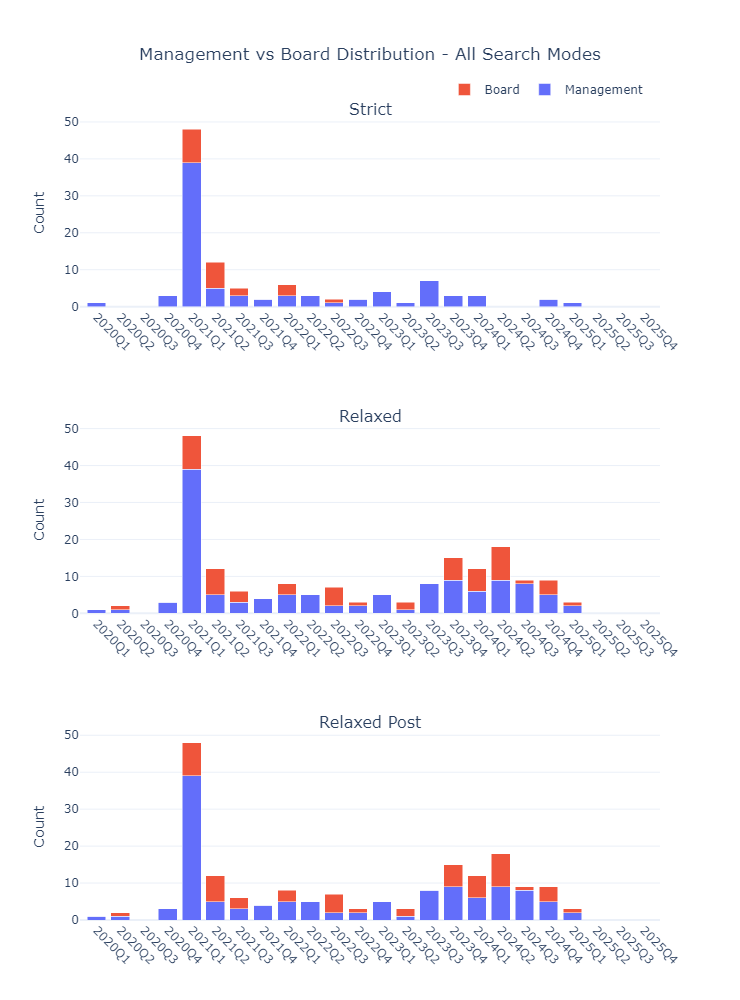
Temporal Pattern Analysis
- Coverage Volume: Quarterly document counts for the monitored individual across different periods
- Search Mode Comparison: Visual comparison of different approaches
- Activity Peaks: Identification of periods with heightened media attention
Key Insights and Analysis
Coverage Analysis:
- Strict Mode captures the most precise mentions with company co-occurrence
- Relaxed Mode provides comprehensive coverage but may include false positives
- Relaxed Post Mode offers balanced precision-recall by post-filtering for company mentions
- Peak activity period in Strict Mode: 2021Q1
- Peak activity period in Relaxed Mode: 2021Q1
Source Analysis
Analyze which news sources provide the most coverage for comprehensive media monitoring: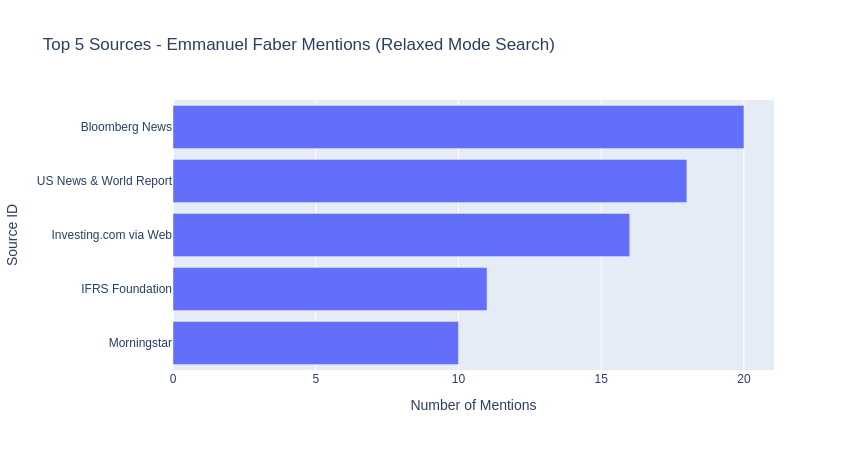
Export the result
Create and export comprehensive summary for reporting and further analysis:Conclusion
The Board Management Monitoring workflow provides a comprehensive automated framework for tracking individuals across news coverage with multiple precision levels. By systematically combining entity tracking with temporal analysis, this workflow transforms scattered media mentions into structured intelligence for governance and risk assessment. Through automated multi-mode monitoring, you can:- Track individual exposure - Monitor specific board members and executives across comprehensive news coverage with varying levels of precision and recall
- Compare search strategies - Utilize multiple search modes to balance precision and recall based on specific monitoring requirements
- Analyze coverage volume - Quantify media attention intensity across quarterly periods and identify peaks in coverage
- Monitor source diversity - Track which news outlets provide the most coverage for comprehensive media monitoring
- Generate structured datasets - Export processed results with metadata for further qualitative analysis and reporting