Why It Matters
Credit rating changes or outlook revisions can have immediate effects on corporate bond spreads, equity valuations, and counterparty risk assessments. For traders, portfolio managers, and credit analysts, staying ahead of these developments is critical to anticipate market reactions and adjust exposure before the news is fully priced in.What It Does
This workflow systematically detects, labels, and summarizes event-related news for a selected watchlist of companies and entities using the Bigdata API for content retrieval and large language models for feature extraction. By customizing the prompts, keywords, and parameters, this framework can be adapted to monitor any type of corporate event or regulatory development - from credit ratings and earnings announcements to regulatory changes and strategic developments. The output includes both structured datasets and analytical reports for monitoring or backtesting.How It Works
The workflow implements a four-step agentic pipeline built on Bigdata API:- Content Retrieval & Enhancement: Search for entities and event-specific keywords using the Bigdata Search API. Run queries over configurable time windows with parallel processing, collecting raw content with metadata and enriching results with surrounding context.
- Feature Extraction & Validation: Use LLM-powered analysis to identify entity relationships, extract structured event features, and validate classifications. The prompts can be customized to extract any necessary features for different event types and domains.
- Advanced Analytics Generation: Derive timestamped analytics with event-specific scoring and sentiment analysis tailored to your monitoring requirements.
- Report Generation: Produce dated timelines of events with supporting quotes, source links, and exportable datasets for further analysis or integration into existing workflows.
A Real-World Use Case
This cookbook demonstrates the complete workflow through a practical example: tracking credit rating updates and outlook revisions for Tesla over a three-year period. You’ll learn how to transform unstructured rating-related news into structured insights that highlight rater-ratee relationships, analyst commentary, and market implications. Ready to get started? Let’s dive in!Prerequisites
To run the Credit Ratings Monitoring workflow, you can choose between two options:-
💻 GitHub cookbook
- Use this if you prefer working locally or in a custom environment.
- Follow the setup and execution instructions in the
README.md. - API keys are required:
- Option 1: Follow the key setup process described in the
README.md - Option 2: Refer to this guide: How to initialise environment variables
- ❗ When using this method, you must manually add the OpenAI API key:
- ❗ When using this method, you must manually add the OpenAI API key:
- Option 1: Follow the key setup process described in the
-
🐳 Docker Installation
- Docker installation is available for containerized deployment.
- Provides an alternative setup method with containerized deployment, simplifying the environment configuration for those preferring Docker-based solutions.
Setup and Imports
Async Compatibility Setup
Run this cell first - Required for Google Colab, Jupyter Notebooks, and VS Code with Jupyter extension:Defining Your Event Monitoring Parameters
To perform an event monitoring and feature extraction analysis, you need to define a few key parameters:- Company Names (
company_names): The set of companies to monitor events for (e.g. your portfolio or watchlist) - Rating Agencies Names (
rating_agencies_names): (Optional) The list of entities you want to be co-mentioned with your entities and events - Keywords (
keywords): The keywords characterizing the event - Time Period (
start_date_queryandend_date_query): The date range over which to run the search - Frequency (
frequency): The frequency of the date ranges to search over. Supported values:Y: Yearly intervals.M: Monthly intervals.W: Weekly intervals.D: Daily intervals
- Document Limit (
document_limit): The maximum number of documents to return per query to Bigdata API. - Batch Size (
batch_size): The number of entities to include in a single batched query. - Document Type (
document_type): Specify which documents to search over (transcripts, filings, news) - Model Selection (
llm_model): The AI model used for semantic analysis and topic classification
Portfolio Selection
Define your watchlist starting from the companies name. For the purpose of this example, the workflow selects Tesla. The Entity ID is retrieved by leveraging Bigdata.com’s Knowledge Graph.Content Retrieval from Bigdata Search API
The workflow searches news content using the Bigdata API to find articles mentioning Tesla, rating agencies, and credit rating keywords. The search runs across daily windows with parallel processing for efficiency. Thesearch_enhanced function retrieves not only the matching text chunks but also their surrounding context (previous and next paragraphs) to provide richer information for analysis.
Results are stored in the contextualized_chunks DataFrame for feature extraction.
Features Augmentation
Entity Role Detection
The LLM agent is prompted to label the sentences extracted to identify the role played by the entities detected in each sentence, detecting raters and ratees. A unique identifier for the tuple of entity name, document headline, and augmented text is created and the content is sent to the LLM for role detection.Entity Role Validation
Subsequently, the LLM agent is prompted to validate the roles identified in the previous steps. The original text, the label assigned and the motivation are provided, and the LLM is instructed to either confirm or correct the role assigned to each entity.Credit Features Extraction
The LLM is instructed to augment the features related to long-term and short-term credit ratings, credit outlooks, and analysts’ comments in a multi-step approach leveraging three different prompts. The prompts can be customized to extract any necessary features. Prompt 1 is designed to extract the following:- Credit Rating: Extract the overall credit rating assigned to Tesla.
- Credit Action: Extract any change or affirmation of the credit rating assigned to Tesla, categorized as:
- Upgrade: An improvement in the rating.
- Downgrade: A decrease in the rating.
- Affirmed: Rating confirmed with no change.
- Corrected: Adjusted due to an error.
- Withdrawn: The rating is removed.
- Reinstated: A withdrawn rating is restored.
- Credit Status: Any additional information regarding the credit rating status, categorized as:
- Provisional Rating: A preliminary rating.
- Matured or Paid in Full: When the obligation reaches maturity.
- No Rating: Rating declined or unavailable.
- Published: Officially issued or announced.
- Credit Outlook: The credit outlook mentioned by the rater, and any related mention of the credit rating assessed in the coming weeks, months or years.
- Positive: Suggests potential improvement.
- Negative: Indicates potential downgrade.
- Stable: No expected change.
- Developing: Change possible based on future events.
- Credit Watchlist: Any mention of Tesla being placed in a credit watchlist for review of the credit rating. Labelled as:
- Watch: The rating is on a watchlist.
- Watch Positive: Potential upgrade.
- Watch Negative: Suggests downgrade.
- Watch Removed: No longer active.
- Watch Unchanged: Status remains without change in expectation.
- Short Term Credit Rating: Any credit rating assigned to Tesla and specifically referred to a short-term debt instrument, if mentioned.
- Long Term Credit Rating: Any credit rating assigned to Tesla and specifically referred to a long-term debt instrument, if mentioned.
- Debt Instrument: The debt instruments under study.
- Key Drivers: Any motivating the credit rating or outlook decision, and influencing the credit quality of the ratee entity, including, but not limited to:
- Cash flow generation (e.g. earnings, revenues, dividends, assets)
- Insider trading, stock prices, stock picks
- Capital structure changes (e.g. equity actions, acquisitions, mergers)
- Forward Guidance: Capture any forward guidance discussed regarding current or future credit ratings, including any potential changes or outlook updates.
Deriving a Structured Dataframe of Advanced Analytics
The workflow provides a timestamped dataframe of credit ratings news with advanced analytics generated through the feature augmentation process. This dataset can be exported in CSV for Excel for further analysis, such as validation, augmentation, or backtesting.View Full Dataset (First 5 Rows with All Columns)
View Full Dataset (First 5 Rows with All Columns)
Report Generation
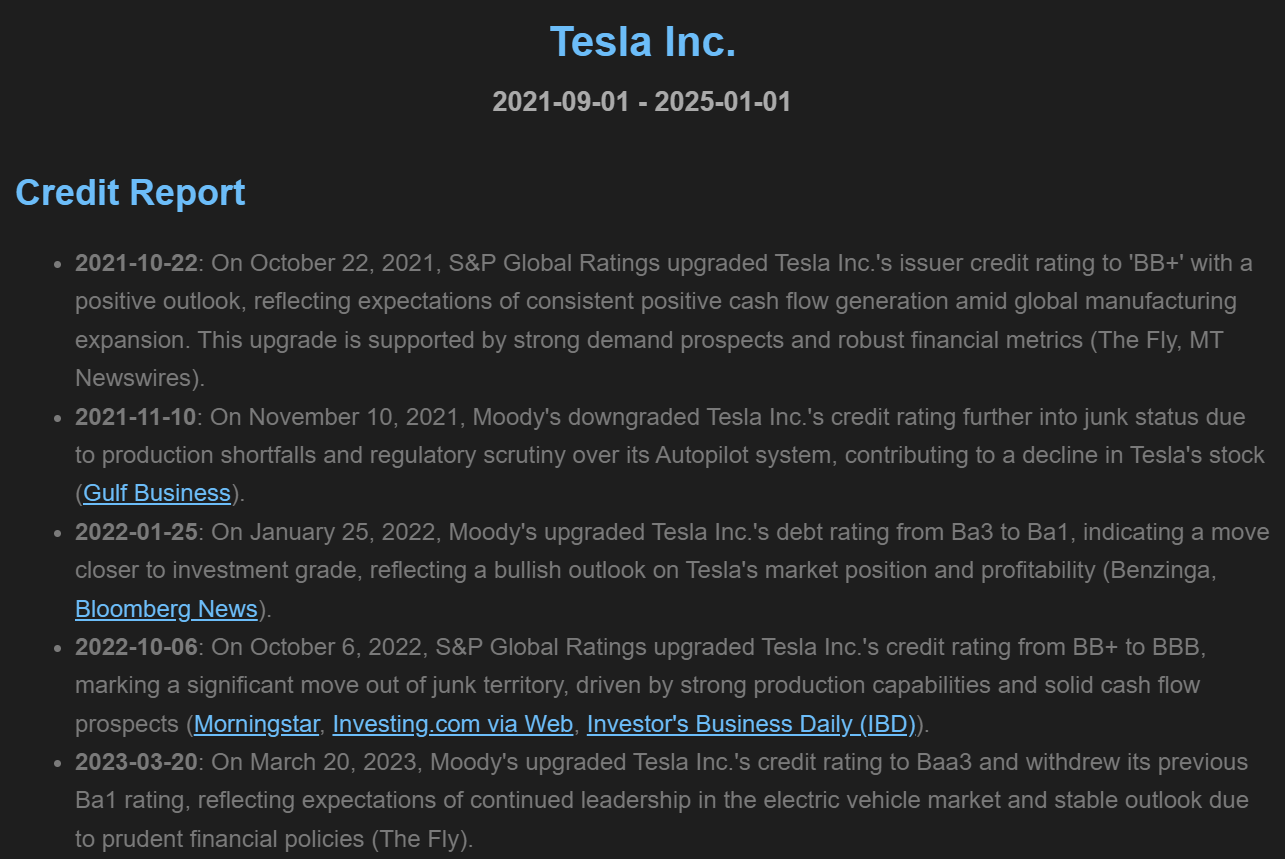
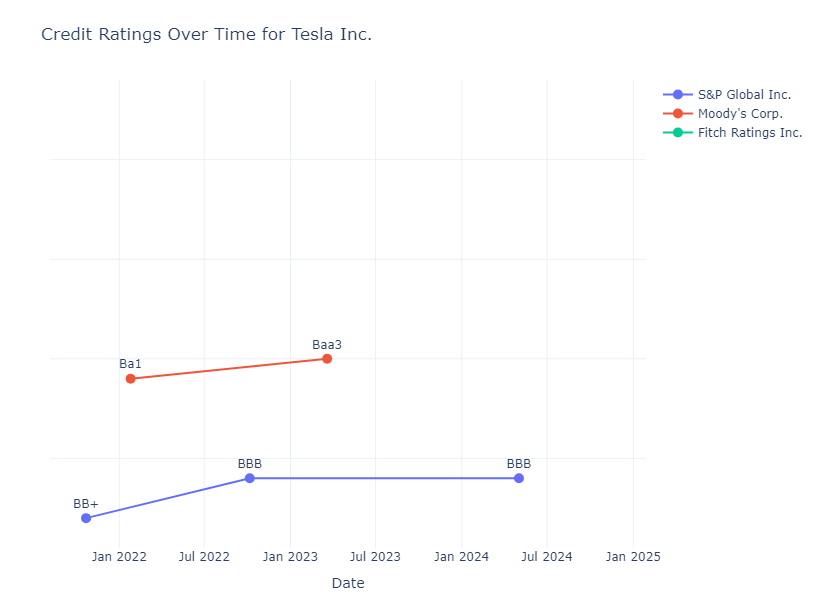
In this step, the workflow summarizes the timeline of credit ratings news. Summarization is performed in two steps, removing duplicates and repeated events by generating daily summaries and generating a timeline that highlights new information. Alongside the timeline of events, the workflow creates a final table which synthetizes the credit rating changes by rating agency, and visualizes it in an interactive plot.Save and Display Reports
Reports and tables can be customized and exported as HTML files for further analysis.Tesla Inc.
Export the Results
Export the results for further analysis or to share with the team.Conclusion
The Credit Ratings Monitoring provides a comprehensive automated framework for tracking and analyzing credit rating events across your portfolio or watchlist. By systematically combining advanced information retrieval with LLM-powered feature extraction, this workflow transforms unstructured news data into actionable intelligence for credit analysis and risk management. Through the automated analysis of credit rating dynamics, you can:- Monitor rating changes in real-time - Stay ahead of upgrades, downgrades, and outlook revisions that could impact bond spreads and equity valuations
- Extract structured insights - Transform narrative credit news into structured features including rating actions, outlooks, watchlist status, and key drivers
- Generate actionable reports - Produce timestamped timelines and exportable datasets for backtesting, portfolio management, and regulatory compliance
- Analyze market implications - Connect credit events to forward guidance and analyst commentary to anticipate market reactions