Why It Matters
Understanding inflation dynamics requires systematic analysis of complex, interconnected factors across the economy. Manually tracking inflation drivers across thousands of news reports, economic data releases, and market commentaries is time-consuming and prone to human bias. As inflation remains a critical concern for policymakers, investors, and analysts, there’s an urgent need for scalable, systematic approaches to monitor inflation themes.What It Does
This workflow is a Macroeconomic Drivers Tracker that breaks down US Inflation into its main components and drivers, then analyzes detailed news reports to extract insights in a structured analytical report. Built for analysts, portfolio managers, and economic researchers, it transforms scattered economic narratives into structured intelligence about inflation dynamics.How It Works
The workflow combines LLM-powered theme taxonomies, semantic content retrieval, and structured reporting methodologies to deliver:- Automated theme breakdown into specific inflation components and drivers
- Systematic document analysis using embeddings-based search and classification
- Economic categorization that turns narrative signals into structured insights
- Comprehensive reporting with analytical summaries for each inflation driver
A Real-World Use Case
This cookbook demonstrates a complete inflation tracking workflow for United States Inflation in 2025, analyzing news coverage from January to February 2025 to identify key inflationary pressures, categorize their economic nature, and generate a professional analytical report. Ready to get started? Let’s dive in!Prerequisites
To run the Inflation Tracking workflow, you can choose between two options:-
💻 GitHub cookbook
- Use this if you prefer working locally or in a custom environment.
- Follow the setup and execution instructions in the
README.md. - API keys are required:
- Option 1: Follow the key setup process described in the
README.md - Option 2: Refer to this guide: How to initialise environment variables
- ❗ When using this method, you must manually add the OpenAI API key:
- ❗ When using this method, you must manually add the OpenAI API key:
- Option 1: Follow the key setup process described in the
-
🐳 Docker Installation
- Docker installation is available for containerized deployment.
- Provides an alternative setup method with containerized deployment, simplifying the environment configuration for those preferring Docker-based solutions.
Setup and Imports
Below is the Python code required for setting up the environment and importing necessary libraries.Defining Inflation Analysis Parameters
- Main Theme (
main_theme): The central macroeconomic concept to explore - Time Period (
start_dateandend_date): The date range over which to run the search - Document Type (
document_type): Specify which documents to search over (transcripts, filings, news) - Model Selection (
llm_model): The LLM model used to mindmap the theme and label the search result chunks - Rerank Threshold (
rerank_threshold): By setting this value, you’re enabling the cross-encoder which reranks the results and selects those whose relevance is above the percentile you specify (0.7 being the 70th percentile) - Focus (
focus): Specify a focus within the main theme. This will then be used in building the LLM generated mindmapper - Source Country (
source_country): Specify the country from which the document originates - Frequency (
freq): The frequency of the date ranges to search over. Supported values:Y: Yearly intervalsM: Monthly intervalsW: Weekly intervalsD: Daily intervals. Defaults toM
- Document Limit (
document_limit): The maximum number of documents to return per query to Bigdata API - Batch Size (
batch_size): The number of entities to include in a single batched query - Sort By (
sortby): Parameter to rank the search results
Mindmap a Theme Taxonomy with Bigdata Research Tools
You can leverage Bigdata Research Tools to generate a comprehensive theme taxonomy with an LLM, breaking down a theme into smaller, well-defined concepts or sub-themes for more targeted analysis. In this case we are able to extract the drivers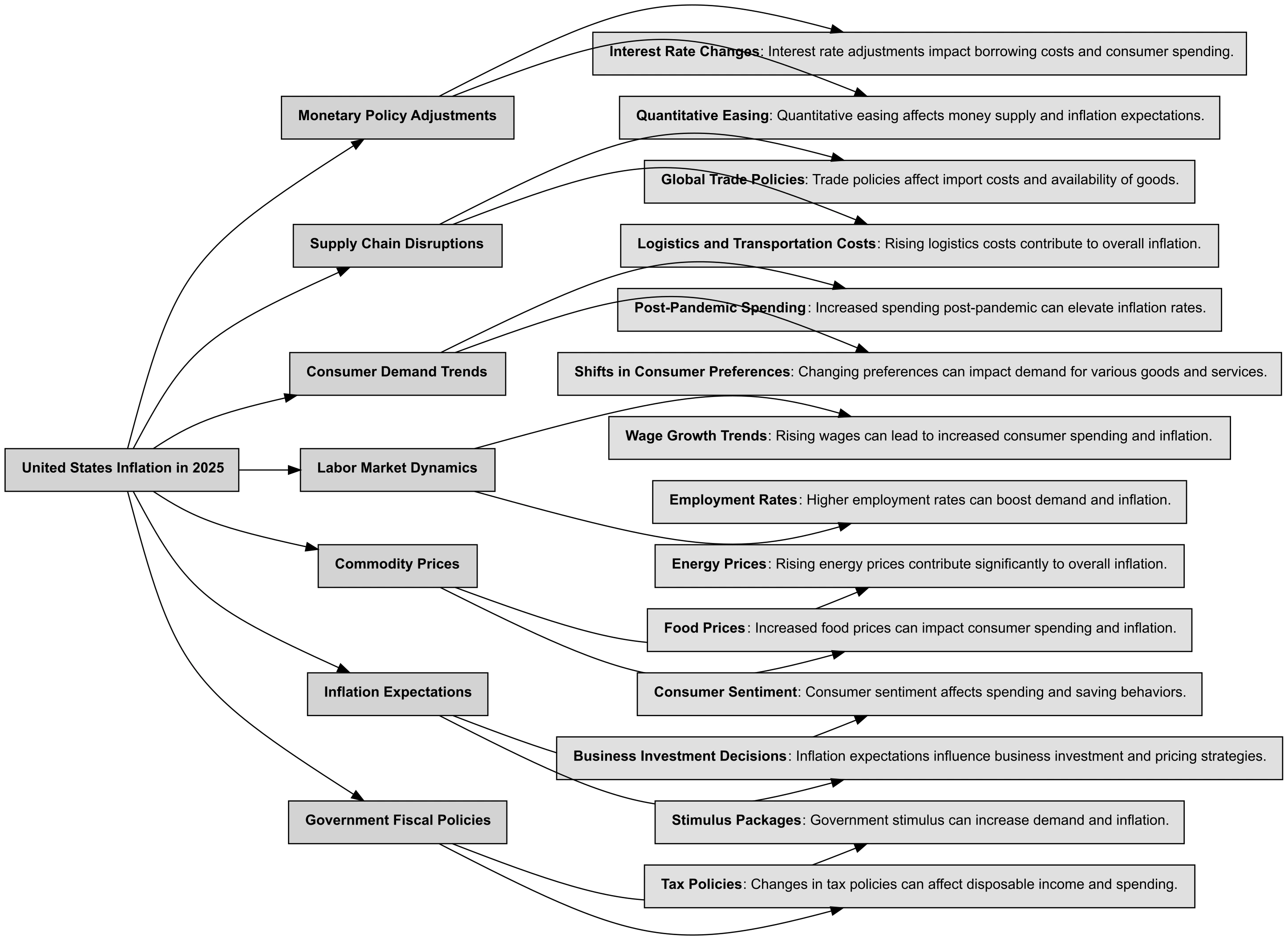
Retrieve Content using Bigdata’s Search Capabilities
With the theme taxonomy and screening parameters, you can leverage the Bigdata API to run a search across all the news.Label the Results
Use an LLM to analyze each text chunk and determine its relevance to the inflation sub-themes. Any chunks which aren’t explicitly linked to US inflation components will be filtered out.Text Summarization
This process concatenates all the text for a given label and instructs an LLM to summarize the text retrieved for each driver. The LLM is specifically instructed to generate an analytical summary that is rich in insights and figures, and excludes events and numbers that are outside of the timeframe of the report.drivers_tags
Generate the Report
As a final step, an LLM uses the last dataframe to generate a brief introduction for the report, summarizing the contents in a few sentences. The report is then formatted and composed by organizing it by the key driver labels defined above and rendering it in HTML format.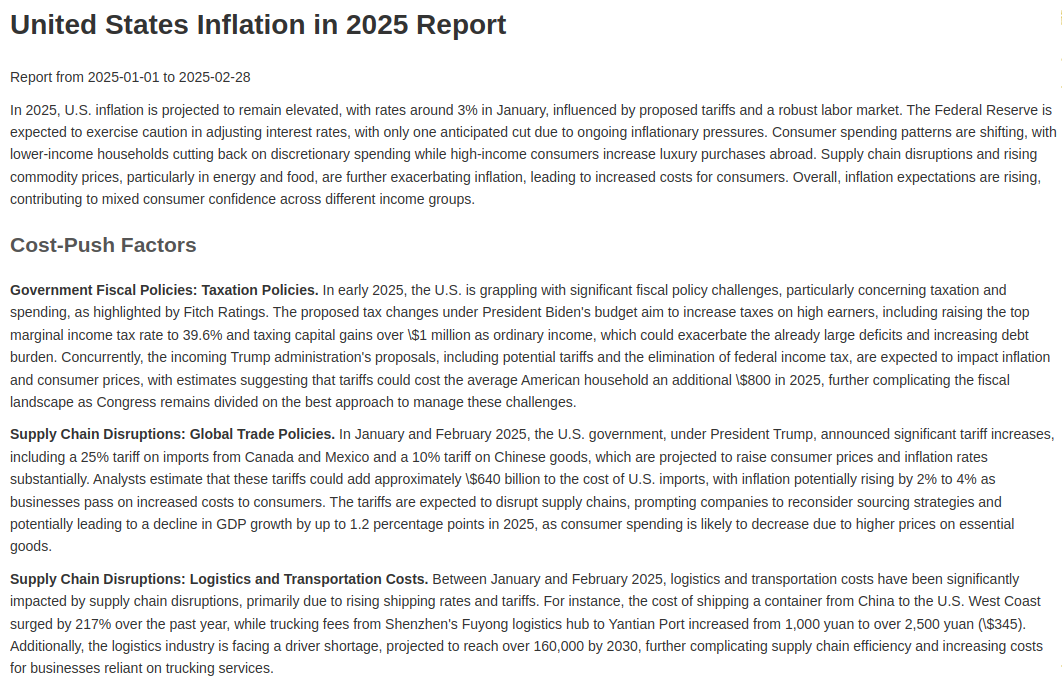
Export the Results
Export the data as Excel files for further analysis or to share with the team.Conclusion
The Inflation Tracking workflow provides a comprehensive automated framework for monitoring and analyzing US inflation dynamics across multiple economic dimensions. By systematically combining advanced information retrieval with LLM-powered categorization, this workflow transforms unstructured news data into structured intelligence for economic analysis and decision-making. Through automated analysis of inflation drivers and their economic categorization, analysts can:- Identify Key Inflation Pressures - Systematically discover and quantify the primary drivers of inflation across different economic sectors and categories
- Categorize Driver Types - Automatically classify inflation pressures according to established economic frameworks (demand-pull, cost-push, monetary policy, etc.)
- Generate Professional Reports - Create comprehensive, evidence-based reports that can inform policy discussions, investment decisions, and economic research
- Scale Economic Analysis - Process thousands of news reports and economic commentaries that would be impossible to analyze manually